

MyBatis源码学习
Mybatis 学习
1. 创建简单的映射器代理工厂
对应 step1.** 包下代码
工程结构
mybatis-step-01
└── src
├── main
│ └── java
│ └── step1.mybatis.binding
│ ├── MapperProxy.java
│ └── MapperProxyFactory.java
└── test
└── java
└── mybatis
├── step1
│ └── MapperProxyTest.java
└── dao
└── IUserDao.java
设计
通常如果能找到大家所在事情的共性内容,具有统一的流程处理,那么它就是可以被凝聚和提炼的,做成通用的组件或者服务,被所有人进行使用,减少重复的人力投入。
而参考最开始使用 JDBC 的方式,从连接、查询、封装、返回,其实都一个固定的流程,那么这个过程就可以被提炼以及封装和补全大家所需要的功能。
当来设计一个 ORM 框架的过程中,首先要考虑怎么把用户定义的数据库操作接口、xml配置的SQL语句、数据库三者联系起来。其实最适合的操作就是使用代理的方式进行处理,因为代理可以封装一个复杂的流程为接口对象的实现类,设计如图:
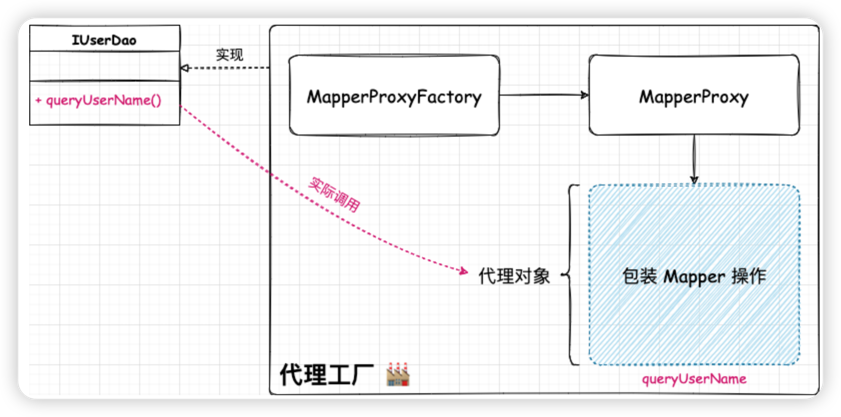
- 首先提供一个映射器的代理实现类
MapperProxy,通过代理类包装对数据库的操作,目前会先提供一个简单的包装,模拟对数据库的调用。 - 之后对
MapperProxy代理类,提供工厂实例化操作MapperProxyFactory#newInstance,为每个 IDAO 接口生成代理类。这块其实用到的就是一个简单工厂模式
总结
- 初步对 Mybatis 框架中的数据库 DAO 操作接口和映射器通过代理类的方式进行链接,这一步也是 ORM 框架里非常核心的部分。有了这块的内容,就可以在代理类中进行自己逻辑的扩展了。
- 在框架实现方面引入简单工厂模式包装代理类,屏蔽创建细节,这些也是大家在学习过程中需要注意的设计模式的点。
- 目前内容还比较简单的,可以手动操作练习,随着内容的增加,会有越来越多的包和类引入,完善 ORM 框架功能。
2. 实现映射器的注册和使用
对应 step2.** 包下代码
代码中包扫描使用了依赖:
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.11</version>
</dependency>
工程结构
mybatis-step-01
└── src
├── main
│ └── java
│ └── step1.mybatis
│ ├── binding
│ │ ├── MapperProxy.java
│ │ ├── MapperProxyFactory.java
│ │ └── MapperRegistry.java
│ └── session
│ ├── SqlSession.java
│ ├── SqlSessionFactory.java
│ └── default
│ └── DefaultSqlSession.java
│ └── DefaultSqlSessionFactory.java
└── test
└── java
└── mybatis
├── step2
│ └── MapperRegistryTest.java
└── dao
│── ISchoolDao.java
└── IUserDao.java
设计
鉴于希望把整个工程包下关于数据库操作的 DAO 接口与 Mapper 映射器关联起来,那么就需要包装一个可以扫描包路径的完成映射的注册器类。
当然还要把step1中简化的 SqlSession 进行完善,由 SqlSession 定义数据库处理接口和获取 Mapper 对象的操作,并把它交给映射器代理类进行使用。这一部分是对step1内容的完善。
有了 SqlSession 以后,你可以把它理解成一种功能服务,有了功能服务以后还需要给这个功能服务提供一个工厂,来对外统一提供这类服务。比如在 Mybatis 中非常常见的操作,开启一个 SqlSession。整个设计如下:
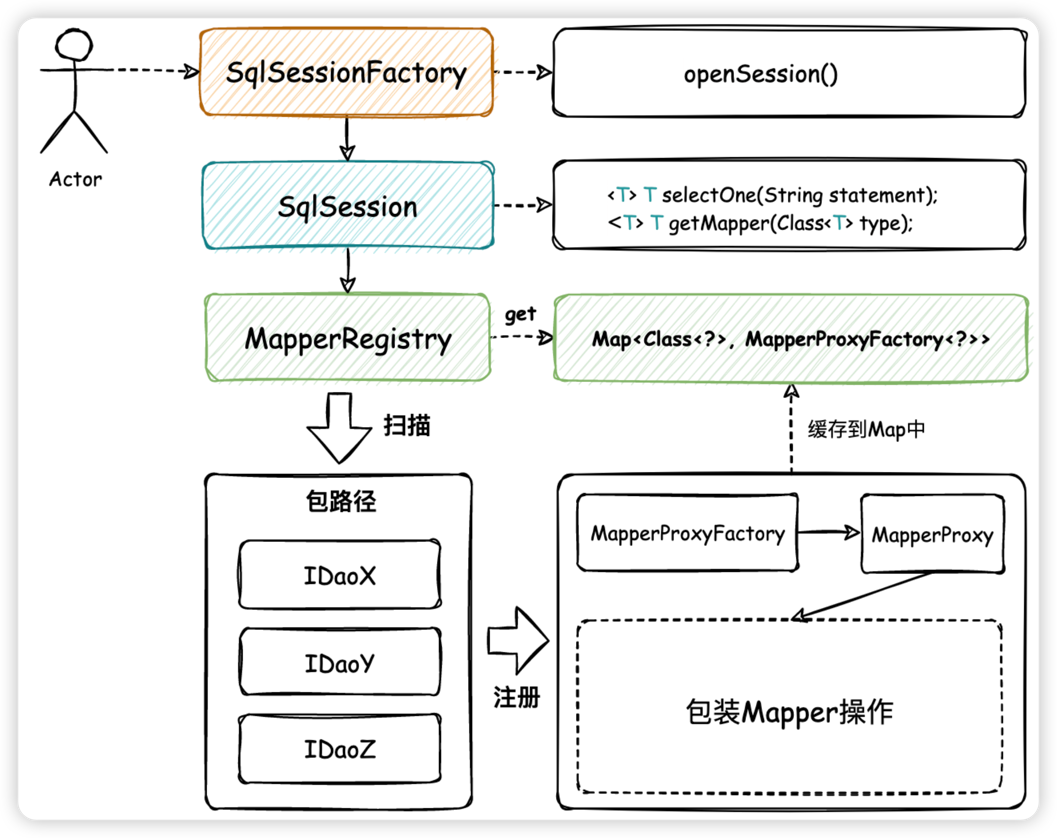
- 以包装接口提供映射器代理类为目标,补全映射器注册机
MapperRegistry,自动扫描包下接口并把每个接口类映射的代理类全部存入映射器代理的 HashMap 缓存中。 - 而 SqlSession、SqlSessionFactory 是在此注册映射器代理的上层使用标准定义和对外服务提供的封装,便于用户使用。把使用方当成用户 经过这样的封装就就可以更加方便后续在框架上功能的继续扩展了,也希望大家可以在学习的过程中对这样的设计结构有一些思考,它可以帮助你解决一些业务功能开发过程中的领域服务包装。
总结
- 首先要从设计结构上了解工厂模式对具体功能结构的封装,屏蔽过程细节,限定上下文关系,把对外的使用减少耦合。
- 从这个过程上读者伙伴也能发现,使用
SqlSessionFactory的工厂实现类包装了 SqlSession 的标准定义实现类,并由 SqlSession 完成对映射器对象的注册和使用。 - 重点: 映射器、代理类、注册机、接口标准、工厂模式、上下文。这些工程开发的技巧都是在手写 Mybatis 的过程中非常重要的部分,了解和熟悉才能更好的在自己的业务中进行使用。
3. Mapper XML的解析和注册使用
对应 step3.** 包下代码
工程结构
mybatis-step-01
└── src
├── main
│ └── java
│ └── step1.mybatis
│ ├── binding
│ │ ├── MapperProxy.java
│ │ ├── MapperProxyFactory.java
│ │ └── MapperRegistry.java
│ └── session
│ ├── SqlSession.java
│ ├── SqlSessionFactory.java
│ └── default
│ └── DefaultSqlSession.java
│ └── DefaultSqlSessionFactory.java
└── test
└── java
└── mybatis
├── step2
│ └── MapperRegistryTest.java
└── dao
│── ISchoolDao.java
└── IUserDao.java
设计
结合之前使用的 MapperRegistry 对包路径进行扫描注册映射器,并在 DefaultSqlSesstion中进行使用。那么在可以吧这些命名空间、Sql描述、映射信息
统一维护到每一个DAO对应的Mapper XML的文件以后,其实XML就是的源头了。通过对XML文件的解析和处理就可以完成Mapper映射器的注册和SQL管理,这样也就更加我
们操作和使用了。
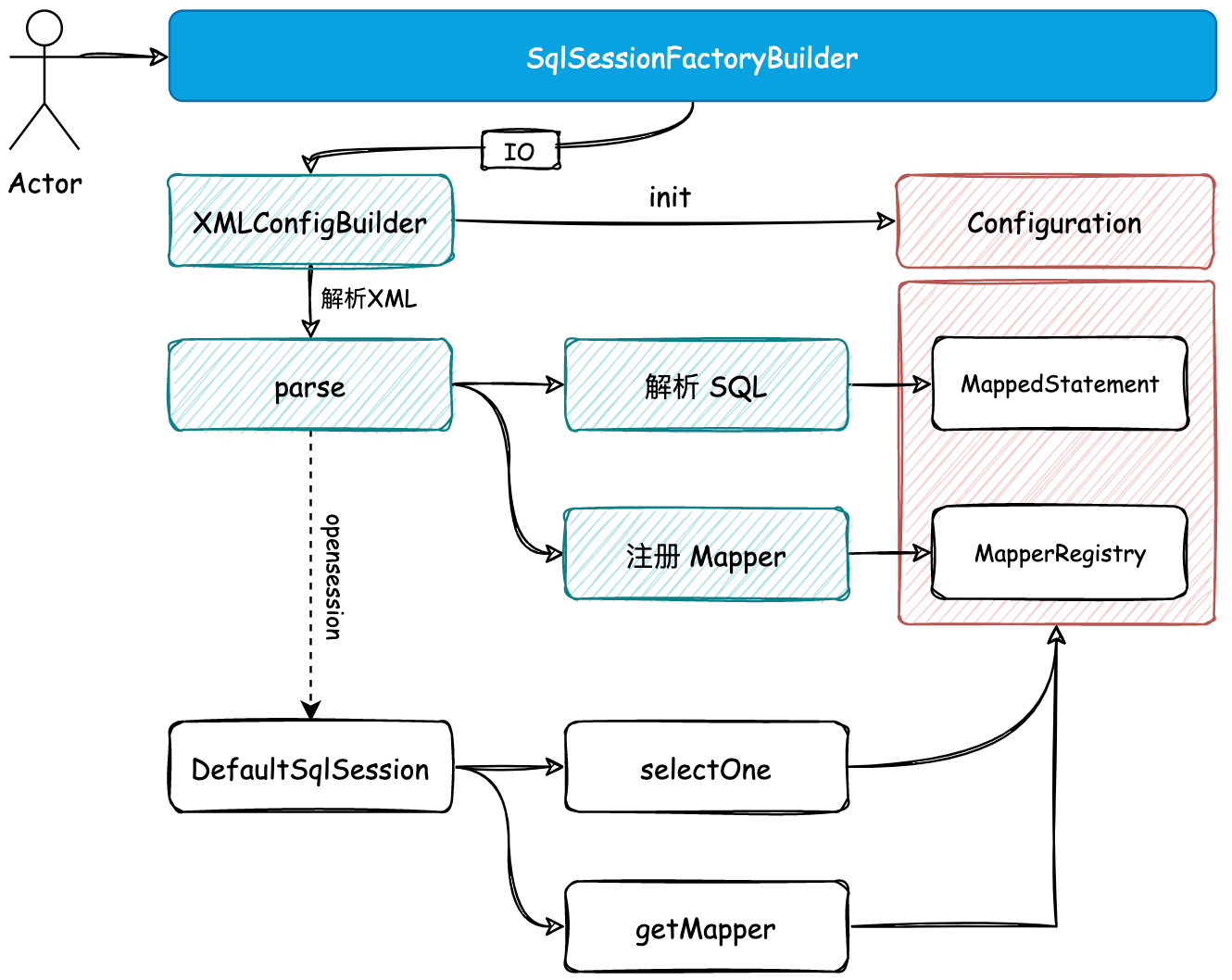
- 首先需要定义
SqlSessionFactoryBuilder工厂建造者模式类,通过入口 IO 的方式对 XML 文件进行解析。当前主要以解析 SQL 部分为主,并注册映射器,串联出整个核心流程的脉络。 - 文件解析以后会存放到 Configuration 配置类中,接下来你会看到这个配置类会被串联到整个 Mybatis 流程中,所有内容存放和读取都离不开这个类。如在 DefaultSqlSession 中获取 Mapper 和执行 selectOne 也同样是需要在 Configuration 配置类中进行读取操作。
总结
- 了解了 ORM 处理的核心流程,知晓目前所处在的步骤和要完成的内容,只有非常清楚的知道这个代理、封装、解析和返回结果的过程才能更好的完成整个框架的实现。
- SqlSessionFactoryBuilder 的引入包装了整个执行过程,包括:XML 文件的解析、Configuration 配置类的处理,让 DefaultSqlSession 可以更加灵活的拿到对应的信息,获取 Mapper 和 SQL 语句。
- 另外从整个工程搭建的过程中,可以看到有很多工厂模式、建造者模式、代理模式的使用,也有很多设计原则的运用,这些技巧都可以让整个工程变得易于维护和易于迭代。这也是研发人员在学习源码的过程中,非常值得重点关注的地方。
4. 数据源的解析、创建和使用
对应 step4.** 包下代码
工程结构:
设计
核心
建立数据源连接池和 JDBC 事务工厂操作,并以 xml 配置数据源信息为入口,在 XMLConfigBuilder 中添加数据源解析和构建操作,向配置类configuration添加 JDBC 操作环境信息。以便在 DefaultSqlSession 完成对 JDBC 执行 SQL 的操作。
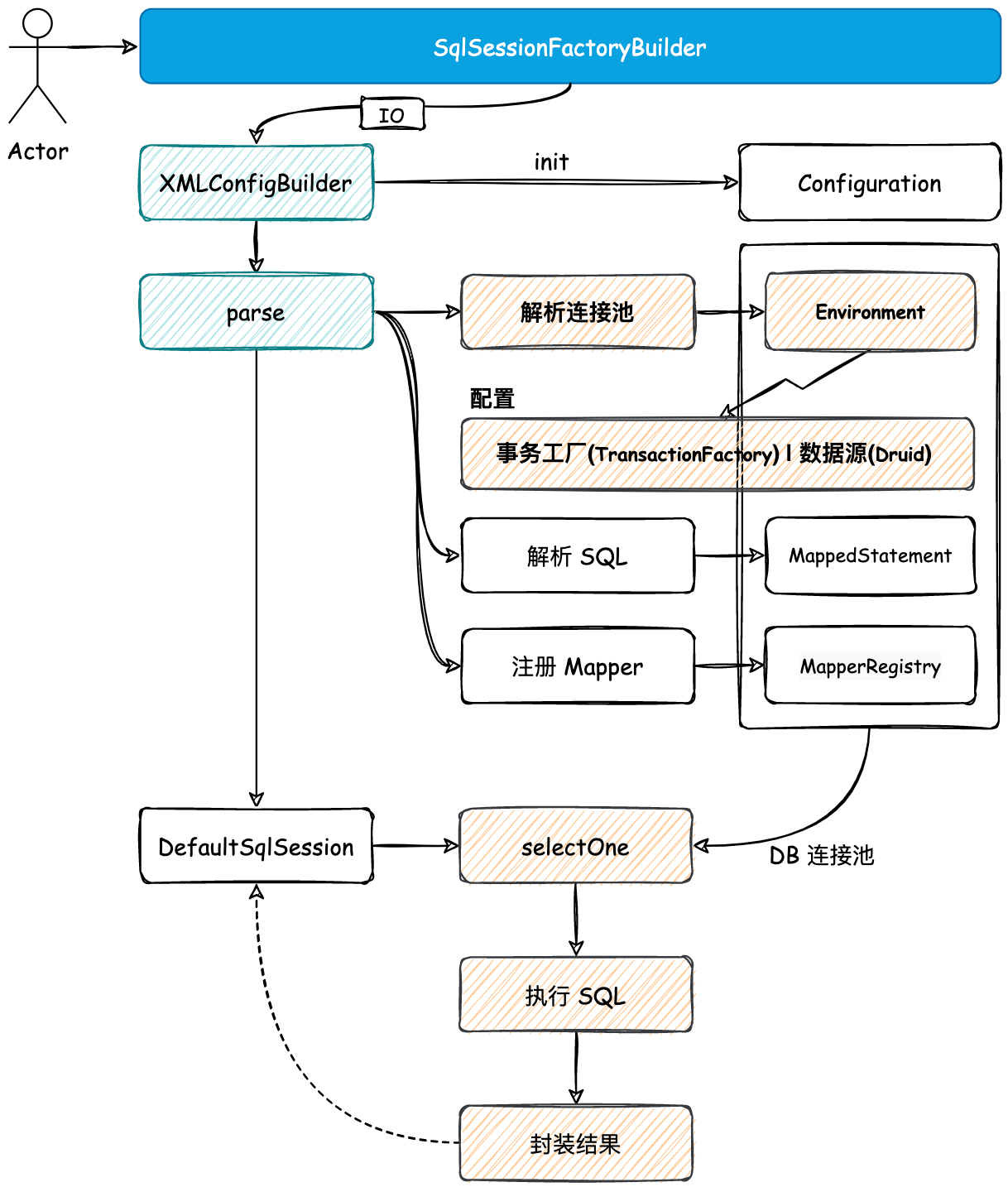
- 在 parse 中解析 XML DB 链接配置信息,并完成事务工厂和连接池的注册环境到配置类的操作。
- 与
step3改造 selectOne 方法的处理,不再是打印 SQL 语句,而是把 SQL 语句放到 DB 连接池中进行执行,以及完成简单的结果封装。
数据源的解析和使用核心类关系:
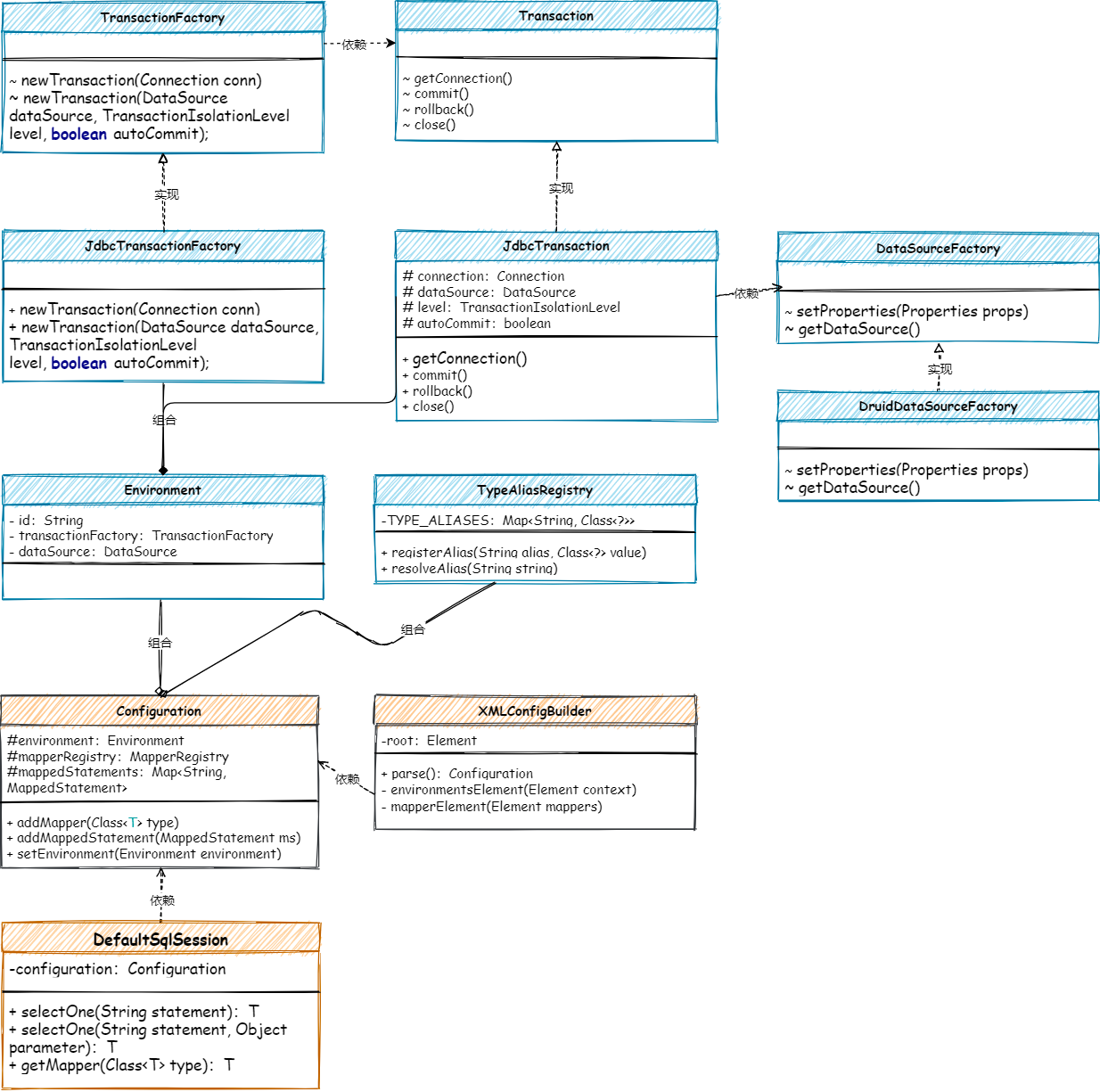
- 以事务接口
Transaction和事务工厂TransactionFactory的实现,包装数据源DruidDataSourceFactory的功能,这里的数据源链接池采用的是阿里的Druid。 - 当所有的数据源相关功能准备好后,就是在
XMLConfigBuilder解析 XML配置操作中,对数据源的配置进行解析以及创建出对应的服务,存放到Configuration的环境配置中。 - 最后在
DeffaultSqlSession#selectOne方法中完成SQL的执行和结果封装,最终把整个MyBatis核心脉络串联出来。
事务管理
一次数据库的操作应该具有事务管理能力,而不是通过 JDBC 获取链接后直接执行即可。还应该把控链接、提交、回滚和关闭的操作处理。所以这里结合 JDBC 的能力封装事务管理。
- 定义标准的事务接口,连接、提交、回滚、关闭,具体可以由不同的事务方式实现,包括:JDBC和托管事务,托管事务是交给Spring这样的容器来管理。
- 在JDBC事务实现中,封装了获取链接、提交事务等操作,其实使用的也就是JDBC本身提供的能力。
- 以工厂方法模式包装JDBC事务实现,为每一个事务实现都提供对应的工厂。与简单工厂的接口包装不同。
类型名注册器
在MyBatis框架中,所需要的基本类型、数组类型以及自己定义的事务实现和事务工厂都需要注册到类型别名的注册器中进行管理,在需要使用的时候可以从注册器获取到具体对象类型,之后再进行实例化的方式进行使用。
- 在
TypeAliasRegisty类型别名注册器中先做了一些基本类型注册,以及提供 registerAlias 注册方法和 resolveAlias获取方法。 - 在
Configuration配置项中,添加类别名注册机,通过构造函数添加JDBC、DRUID注册等操作。 - 整个MyBatis的操作都是使用
Configuration配置项进行串联流程,所以所有内容都会在这个配置项中进行连接。
解析数据源配置
通过在XML解析器 XMLConfigBuilder中,拓展对环境信息的解析,把数据源、事务类内容成为操作SQL的环境。解析后把配置信息写入到Configuration配置项中,便于后续使用。
- 以
XMLConfigBuilder#parse解析扩展对数据源解析操作,在environmentsElement方法中包括事务管理器解析和从类型注册器中读取到事务工程的实现累,同理数据源也是从类型注册器中获取。 - 最后把事务管理器和数据源的处理,通过环境构建
Environment.Builder存放到Configuration配置项中,也就可以通过Configuration存在的地方都获取到数据源了。
SQL执行和结果封装
step3中DefaultSqlSession#selectOne只是打印了XML中配置的SQL语句,现在把数据源的配置加载进来后,就可以把SQL语句放到数据源中进行执行以及结果封装。
- 在
DefaultSqlSession#selectOne方法中,通过Configuration配置项获取到数据源,然后通过数据源获取到链接,最后通过链接执行SQL语句。 - 因为目前这部分主要是为了串联整个功能结构,所以关于SQL的执行、参数传递和结果封装都是写死的。
总结
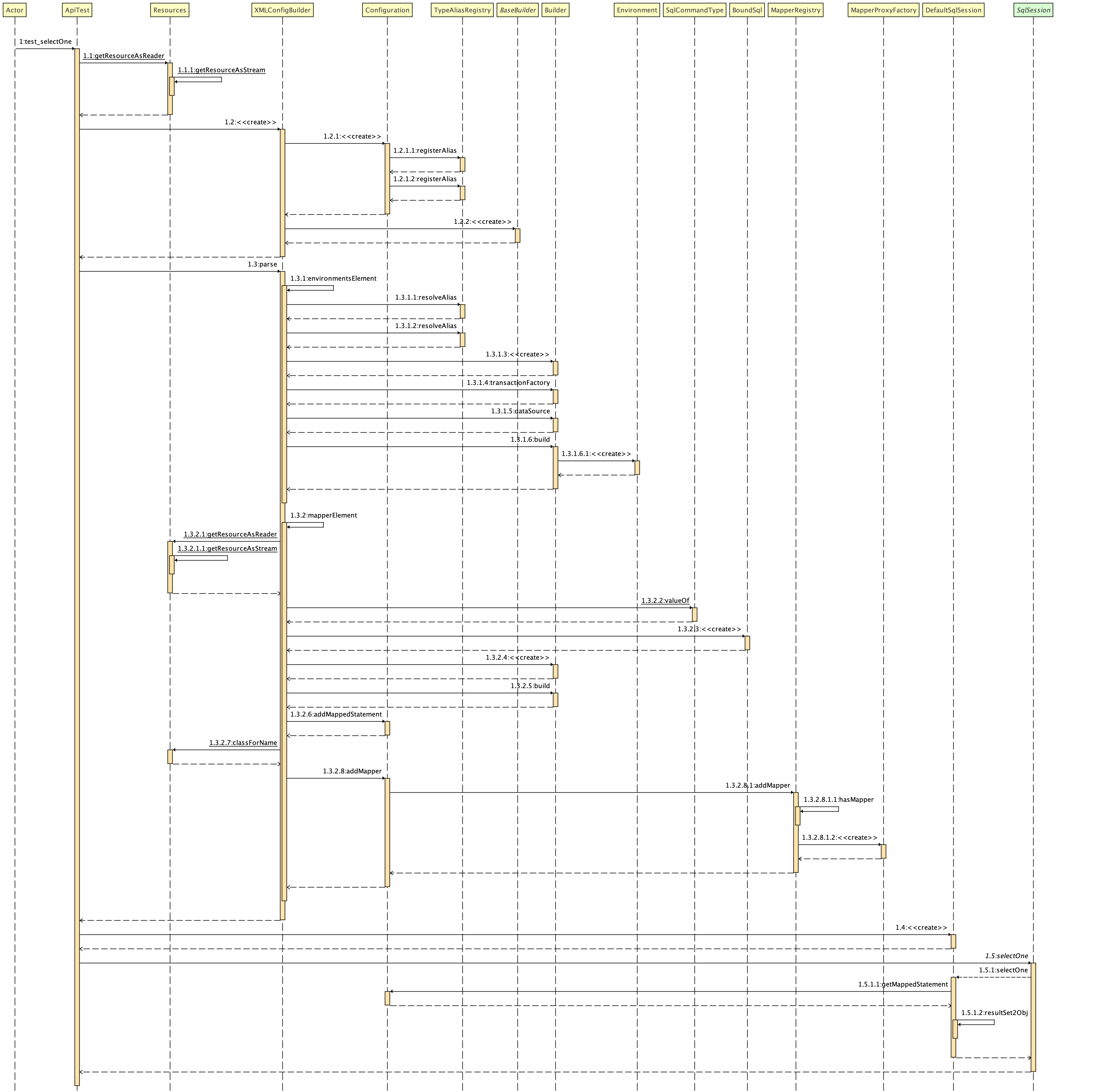
- 以解析XML配置为入口,添加数据源的整合和包装,映出事务工厂对JDBC事务的处理,病加载到环境配置中使用。
- 通过数据源的引入就可以在
DefaultSqlSession从Configuration配置引入环境信息,把对应的SQL语句提交给JDBC进行处理病简单封装结果数据。 - 数据源、事务、简单的SQL调用得以实现。
5. 数据源池化技术实现
工程结构:
设计
核心
池化技术是享元模式的具体实现方案,对于一些需要较高创建成本且高频使用的资源,需要进行缓存或者也称预热处理。并把这些资源存放到一个预热池子中,需要用的时候从池子获取,使用完毕在进行使用。通过池化技术可以有效地控制资源的使用成本。如下图:
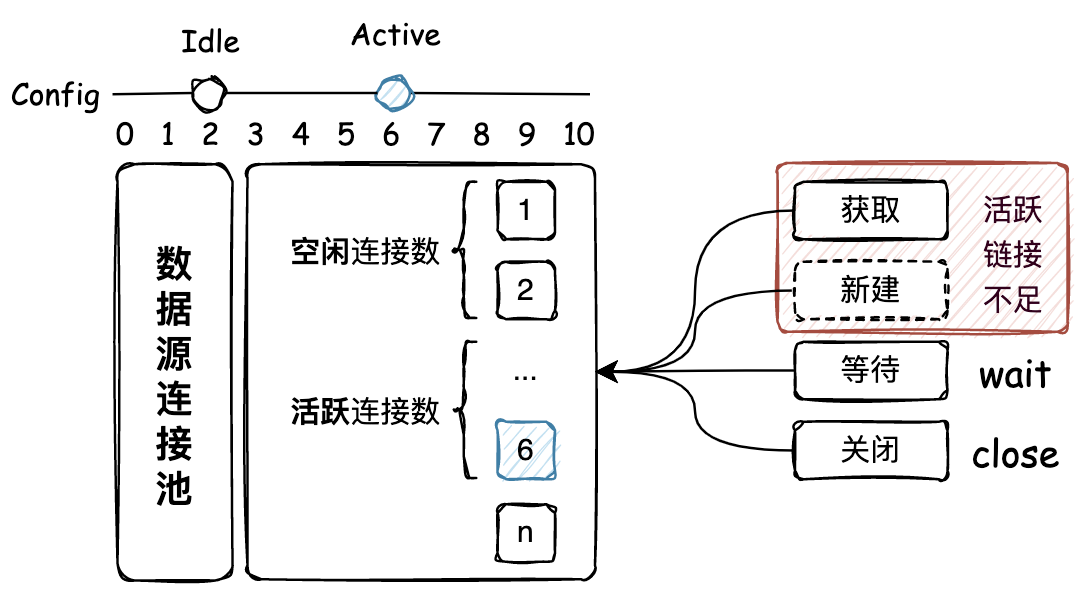
- 通过提供统一的连接池中心,存放数据源链接,并根据配置按照请求获取链接的操作,创建连接池的数据源链接数量。这里就包括了最大空闲链接和最大活跃链接,都随着创建过程被控制。
- 此外由于控制了连接池中连接的数量,所以当外部从连接池获取链接时,如果链接已满则会进行循环等待。这也是大家日常使用DB连接池,如果一个SQL操作引起了慢查询,则会导致整个服务进入瘫痪的阶段,各个和数据库相关的接口调用,都不能获得到链接,接口查询TP99陡然增高,系统开始大量报警。那连接池可以配置的很大吗,也不可以,因为连接池要和数据库所分配的连接池对应上,避免应用配置连接池超过数据库所提供的连接池数量,否则会出现夯住不能分配链接的问题,导致数据库拖垮从而引起连锁反应。
池化数据源核心类关系,如图:
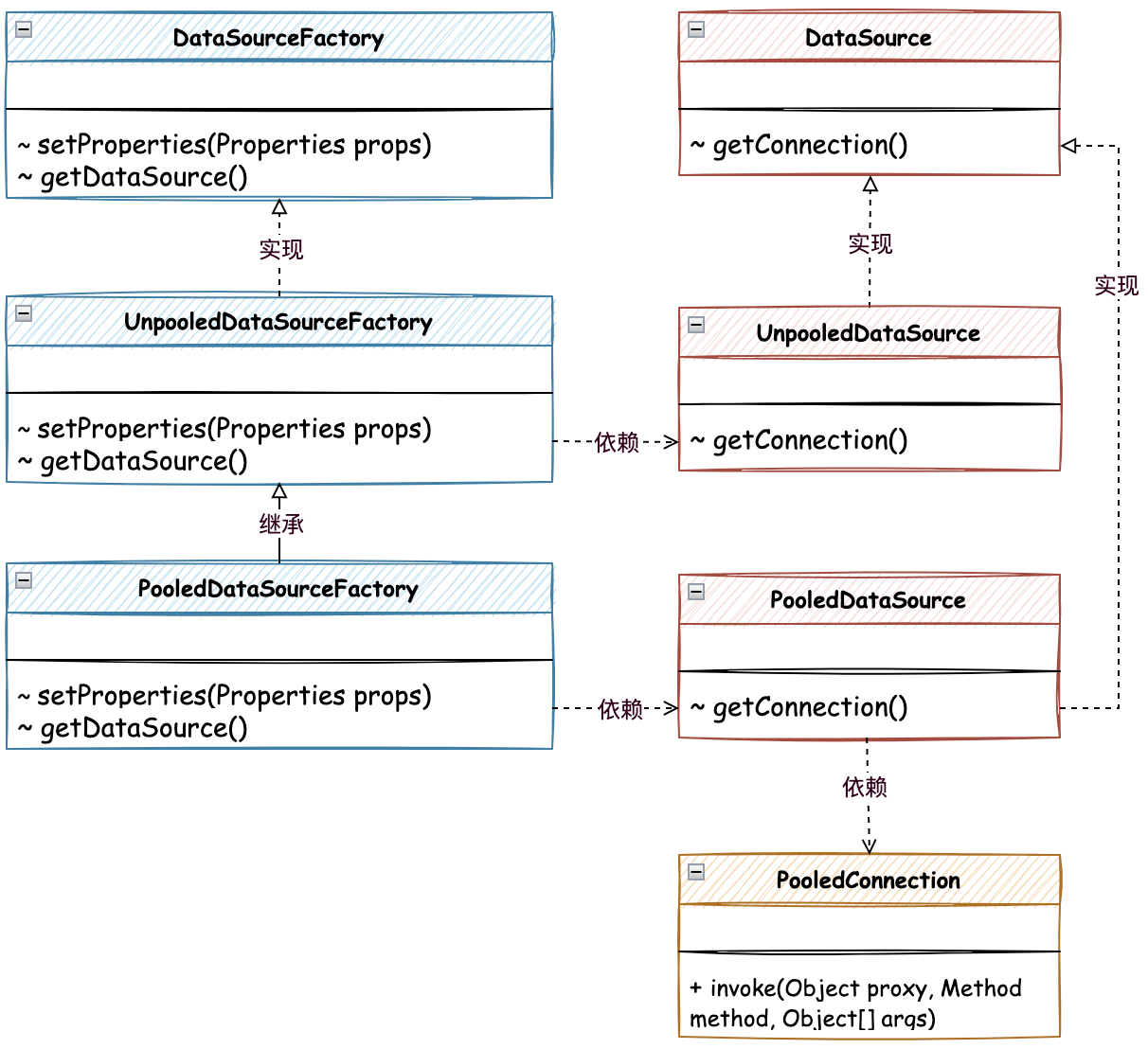
- 在MyBatis数据源的实现中,包括两部分分为无池化的
UnpooleDataSource和池化的PooledDataSource,其中PooledDataSource是UnpooleDataSource的子类,也就是说PooledDataSource是对UnpooleDataSource的扩展。 PooledDataSource是对链接的代理操作,通过 invoke 方法的反射调用,对关闭的链接进行回收处理,并使用 notifyAll 通知正在等待链接的用户进行抢链接。- 另外是对
DataSourceFactory数据源工厂接口的实现,由无池化工厂实现后,有池化工厂继承的方式进行处理,这里没有太多复杂的操作,池化的处理主要集中在PooledDataSource中。
无池化链接实现
对于数据库连接池的实现,不一定非得提供池化技术,对于某些场景可以只是用无池化的连接池。那么在实现的过程中,可以把无池化的实现和池化实现拆分解耦,在需要的时候只需要配置对应的数据源即可。
- 无池化的数据源链接实现比较简单,核心在于
initializerDriver初始化驱动中使用了Class.forName 和 newInstance 的方式创建了数据源链接炒作。 - 在创建完成连接以后,把链接存放到驱动注册器中,方便后续使用中可以直接获取链接,避免重复创建所带来的资源浪费。
有池化链接实现
有池化的数据源链接,核心在于对无池化链接的包装,同时提供了相应的池化技术实现,包括:pushConnection、popConnection、forceCloseAll、pingConnection 的操作处理。
这样当用户想要获取链接的时候,则会从连接池中进行获取,同时判断是否有空闲链接、最大活跃链接多少,以及是否需要等待处理或是最终抛出异常。
- 池化连接的代理
- 通过
PooledConnection实现InvocationHandler#invoke方法,包装代理链接,这样就可以对具体的调用方法进行控制了。 - 在 invoke 方法中处理对 CLOSE 方法控制以外,排除 toString 等Object 的方法后,则是其他真正需要被 DB 链接处理的方法了。
- 那么这里有一个对于 CLOSE 方法的数据源回收操作 dataSource.pushConnection(this); 有一个具体的实现方法,在池化实现类 PooledDataSource 中进行处理。
- 通过
- pushConnection 回收链接
- 在
PooledDataSource#pushConnection数据源回收的处理中,核心在于判断链接是否有效,以及进行相关的空闲链接校验,判断是否把连接回收到 idle 空闲链接列表中,并通知其他线程来抢占。 - 如果现在空闲链接充足,那么这个回收的链接则会进行回滚和关闭的处理中。connection.getRealConnection().close();
- 在
- popConnection 获取链接
- popConnection 获取链接是一个 while 死循环操作,只有获取到链接抛异常才会退出循环,如果仔细阅读这些异常代码,是不是也是你在做一些开发的时候所遇到的异常呢。
- 获取链接的过程会使用 synchronized 进行加锁,因为所有线程在资源竞争的情况下,都需要进行加锁处理。在加锁的代码块中通过判断是否还有空闲链接进行返回,如果没有则会判断活跃连接数是否充足,不充足则进行创建后返回。在这里也会遇到活跃链接已经进行循环等待的过程,最后再不能获取则抛出异常。
数据源工厂
数据源工厂包括两部分,分别是无池化和有池化,有池化的工厂继承无池化工厂,因为在 Mybatis 源码的实现类中,这样就可以减少对 Properties 统一包装的反射方式的属性处理。由于暂时没有对这块逻辑进行开发,只是简单的获取属性传参,所以还不能体现出这样的继承有多便捷,读者可以参考源码进行理解。源码类:UnpooledDataSourceFactory
- 无池化工厂
- 简单包装
getDataSource获取数据源处理,把必要的参数进行传递过去。在 Mybatis 源码中这部分则是进行了大量的反射字段处理的方式进行存放和获取的。
- 简单包装
- 有池化工厂
- 有池化的数据源工厂实现的也比较简单,只是继承
UnpooledDataSourceFactory共用获取属性的能力,以及实例化出池化数据源即可。
- 有池化的数据源工厂实现的也比较简单,只是继承
新增类型别名注册器
当新开发了两个数据源和对应的工厂实现类以后,则需要把它们配置到 Configuration 中,这样才能在解析 XML 时候根据不同的数据源类型获取和实例化对应的实现类。
- 在构造方法
Configuration添加 UNPOOLED、POOLED 两个数据源注册到类型注册器中,方便后续使用XMLConfigBuilder#environmentsElement方法解析 XML 处理数据源时候进行使用。
总结
- 完成了 Mybatis 数据源池化的设计和实现,也能通过这样的分析、实现、验证的过程,更好的理解平常使用的连接池所遇到的一些真实问题都是怎么发生的。
- synchronized 加锁、创建连接、活跃数量控制、休眠等待时长,抛异常逻辑等,这些都与日常使用连接池时的配置息息相关。
6. SQL执行器的定义和实现
工程结构:
设计
核心
ORM框架开发过程中,可以分析出的执行动作包括,解析配置、代理对象、映射方法等,直至对数据源的包装和使用,只不过数据源被硬捆绑到DefaultSqlSession的执行方法上了。
需要对这一块做解耦处理,则需要单独提出一块执行器的服务功能,之后将执行器的功能随着 DefaultSqlSession 创建时传入执行器功能,之后具体的方法调用就可以调用执行器来处理了,从而解耦这部分功能模块。如图:
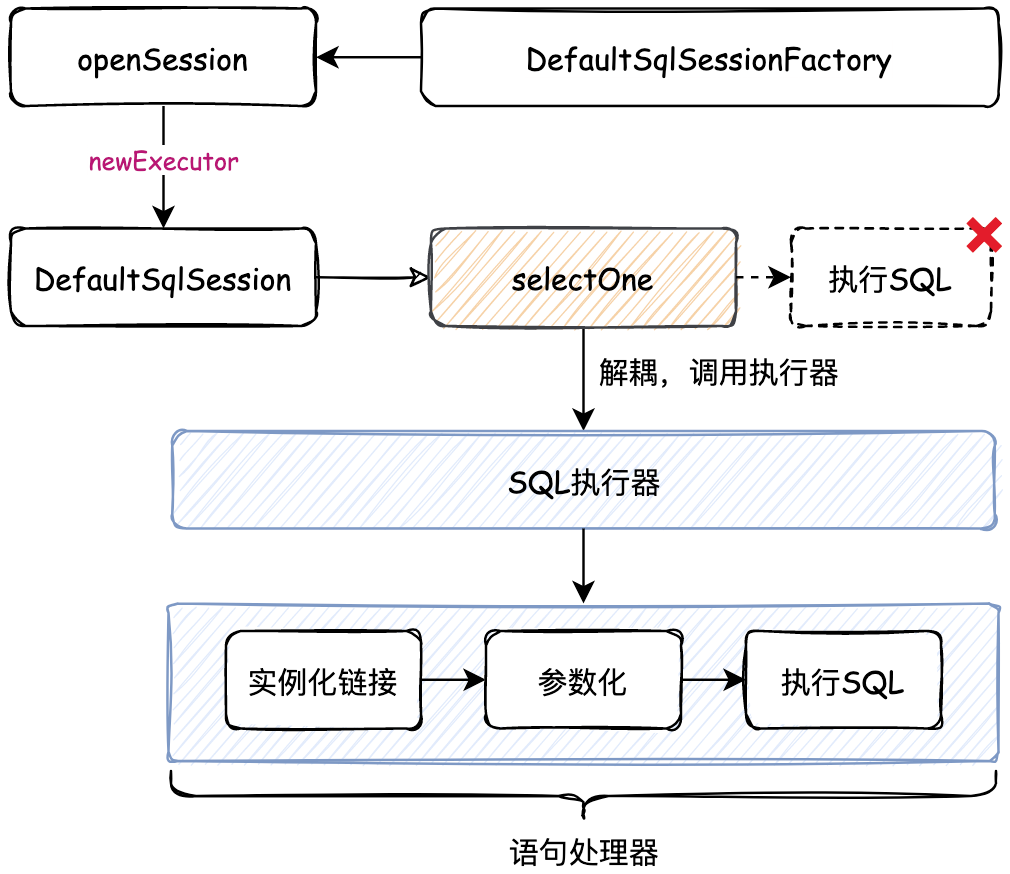
- 首先要提取出执行器的接口,定义出执行方法、事务获取和相应提交、回滚、关闭的定义,同时由于执行器是一种标准的执行过程,所以可以由抽象类进行实现,对过程内容进行模板模式的过程包装。在包装过程中定义抽象类,由具体的子类来实现。这一部分在下文的代码中会体现到
SimpleExecutor简单执行器实现中。 - 之后是对 SQL 的处理,都知道在使用 JDBC 执行 SQL 的时候,分为了简单处理和预处理,预处理中包括准备语句、参数化传递、执行查询,以及最后的结果封装和返回。所以这里也需要把 JDBC 这部分的步骤,分为结构化的类过程来实现,便于功能的拓展。具体代码主要体现在语句处理器
StatementHandler的接口实现中。
SQL方法执行器核心类关系:
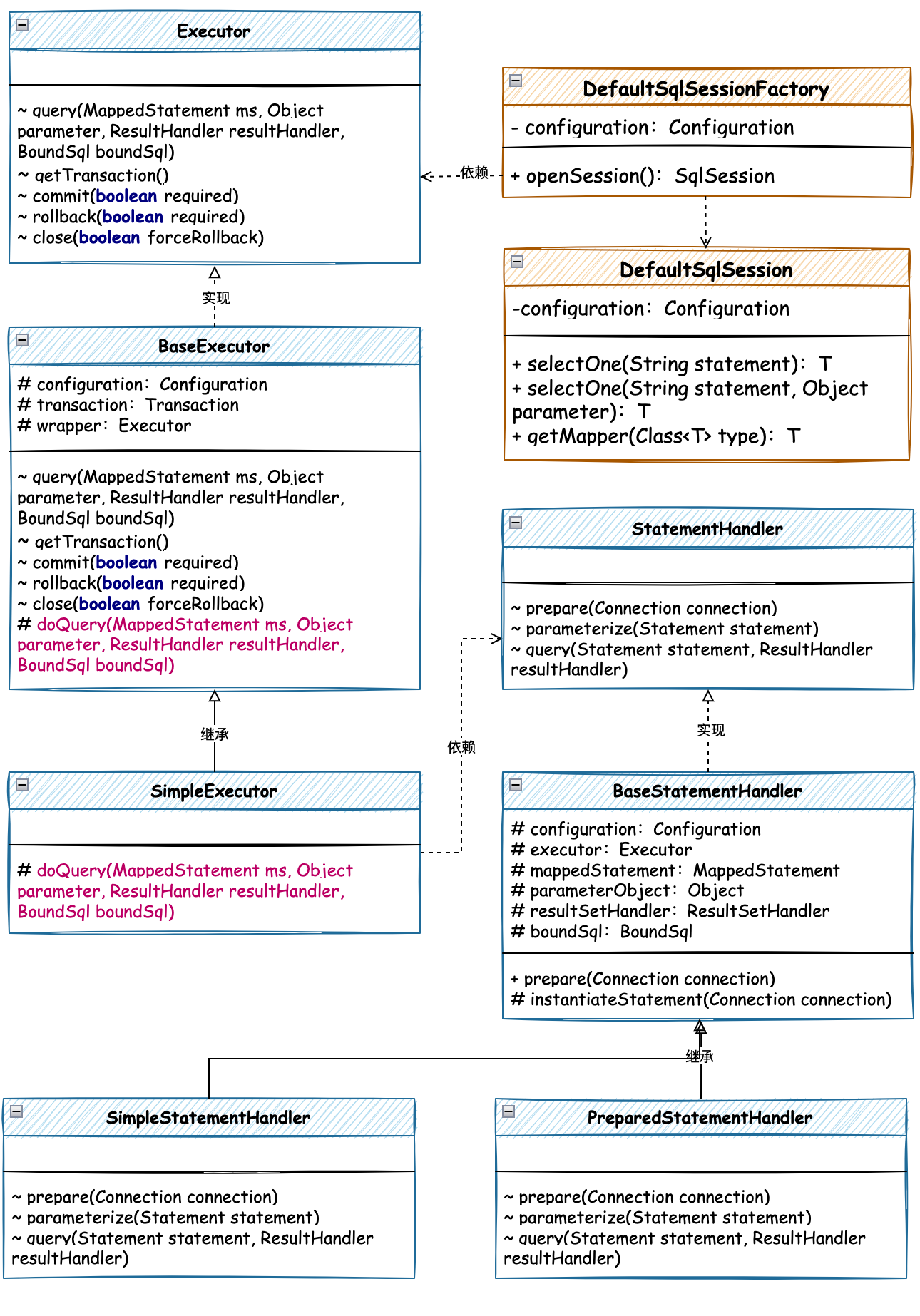
- 以 Executor 接口定义为执行器入口,确定出事务和操作和 SQL 执行的统一标准接口。并以执行器接口定义实现抽象类,也就是用抽象类处理统一共用的事务和执行SQL的标准流程,也就是这里定义的执行 SQL 的抽象接口由子类实现。
- 在具体的简单 SQL 执行器实现类中,处理 doQuery 方法的具体操作过程。这个过程中则会引入进来 SQL 语句处理器的创建,创建过程仍有 configuration 配置项提供。你会发现很多这样的生成处理,都来自于配置项
- 当执行器开发完成以后,接下来就是交给 DefaultSqlSessionFactory 开启 openSession 的时候随着构造函数参数传递给 DefaultSqlSession 中,这样在执行 DefaultSqlSession#selectOne 的时候就可以调用执行器进行处理了。也就由此完成解耦操作了。
执行器的定义和实现
- Executor
- 执行器分为接口、抽象类、简单执行器实现类三部分,通常在框架的源码中对于一些标准流程的处理,都会有抽象类的存在。它负责提供共性功能逻辑,以及对接口方法的执行过程进行定义和处理,并提取抽象接口交由子类实现。这种设计模式也被定义为模板模式。
- 在执行器中定义的接口包括事务相关的处理方法和执行SQL查询的操作,随着后续功能的迭代还会继续补充其他的方法。
- 执行器分为接口、抽象类、简单执行器实现类三部分,通常在框架的源码中对于一些标准流程的处理,都会有抽象类的存在。它负责提供共性功能逻辑,以及对接口方法的执行过程进行定义和处理,并提取抽象接口交由子类实现。这种设计模式也被定义为模板模式。
- BaseExecutor 抽象基类
- 在抽象基类中封装了执行器的全部接口,这样具体的子类继承抽象类后,就不用在处理这些共性的方法。与此同时在 query 查询方法中,封装一些必要的流程处理,如果检测关闭等,在 Mybatis 源码中还有一些缓存的操作,这里暂时剔除掉,以核心流程为主。读者伙伴在学习的过程中可以与源码进行对照学习。
- SimpleExecutor 简单执行器实现
- 简单执行器 SimpleExecutor 继承抽象基类,实现抽象方法 doQuery,在这个方法中包装数据源的获取、语句处理器的创建,以及对 Statement 的实例化和相关参数设置。最后执行 SQL 的处理和结果的返回操作。
语句处理器
语句处理器是 SQL 执行器中依赖的部分,SQL 执行器封装事务、连接和检测环境等,而语句处理器则是准备语句、参数化传递、执行 SQL、封装结果的处理。
- StatementHandler
- 语句处理器的接口定义,包括准备语句、参数化传递、执行查询、结果封装和返回等操作。
- 语句处理器的核心包括了;准备语句、参数化传递参数、执行查询的操作,这里对应的 Mybatis 源码中还包括了 update、批处理、获取参数处理器等
- 语句处理器的接口定义,包括准备语句、参数化传递、执行查询、结果封装和返回等操作。
- BaseStatementHandler 抽象基类
- 在语句处理器基类中,将参数信息、结果信息进行封装处理。不过暂时这里还不会做过多的参数处理,包括JDBC字段类型转换等。这部分内容随着整个执行器的结构建设完毕后,再进行迭代开发。
- 之后是对
BaseStatementHandler#prepare方法的处理,包括定义实例化抽象方法,这个方法交由各个具体的实现子类进行处理。包括;SimpleStatementHandler简单语句处理器和PreparedStatementHandler预处理语句处理器。- 简单语句处理器只是对 SQL 的最基本执行,没有参数的设置。
- 预处理语句处理器则是在 JDBC 中使用的最多的操作方式,
PreparedStatement设置 SQL,传递参数的设置过程。
- PreparedStatementHandler 预处理语句处理器
- 在预处理语句处理器中包括
instantiateStatement预处理 SQL、parameterize 设置参数,以及 query 查询的执行的操作。 - 这里需要注意
parameterize设置参数中还是写死的处理,后续这部分再进行完善。 - query 方法则是执行查询和对结果的封装,结果的封装目前也是比较简单的处理,只是把前面章节中对象的内容摘取出来进行封装,这部分暂时没有改变。都放在后续进行完善处理。
- 在预处理语句处理器中包括
执行器创建和使用
执行器开发完成以后,则需要在串联到 DefaultSqlSession 中进行使用,那么这个串联过程就需要在 创建 DefaultSqlSession 的时候,构建出执行器并作为参数传递进去。那么这块就涉及到 DefaultSqlSessionFactory#openSession 的处理。
- 开启执行器
- 在 openSession 中开启事务传递给执行器的创建。
- 在执行器创建完毕后,则是把参数传递给
DefaultSqlSession,这样就把整个过程串联起来了。
- 使用执行器
- 在 DefaultSqlSession#selectOne 中获取 MappedStatement 映射语句类后,则传递给执行器进行处理,那么现在这个类经过设计思想的解耦后,就变得更加赶紧整洁了,也就是易于维护和扩展了。
总结
- 从
DefaultSqlSession#selectOne对数据源的处理解耦到执行器中进行操作。而执行器中又包括了对 JDBC 处理的拆解,链接、准备语句、封装参数、处理结果,所有的这些过程经过解耦后的类和方法,就都可以在以后的功能迭代中非常方便的完成扩展了。 - 为后续扩展参数的处理、结果集的封装预留出了扩展点,以及对于不同的语句处理器选择的问题,都需要在后续进行完善和补充。目前串联出来的是最核心的骨架结构,随着后续的渐进式开发陆续迭代完善。
7.Mybatis中的反射工具包
工程结构:
设计
核心
如果说需要对一个对象的所提供的属性进行统一的设置和获取值的操作,那么就需要把当前这个被处理的对象进行解耦,提取出它所有的属性和方法,并按照不同的类型进行反射处理,从而包装成一个工具包。如图:
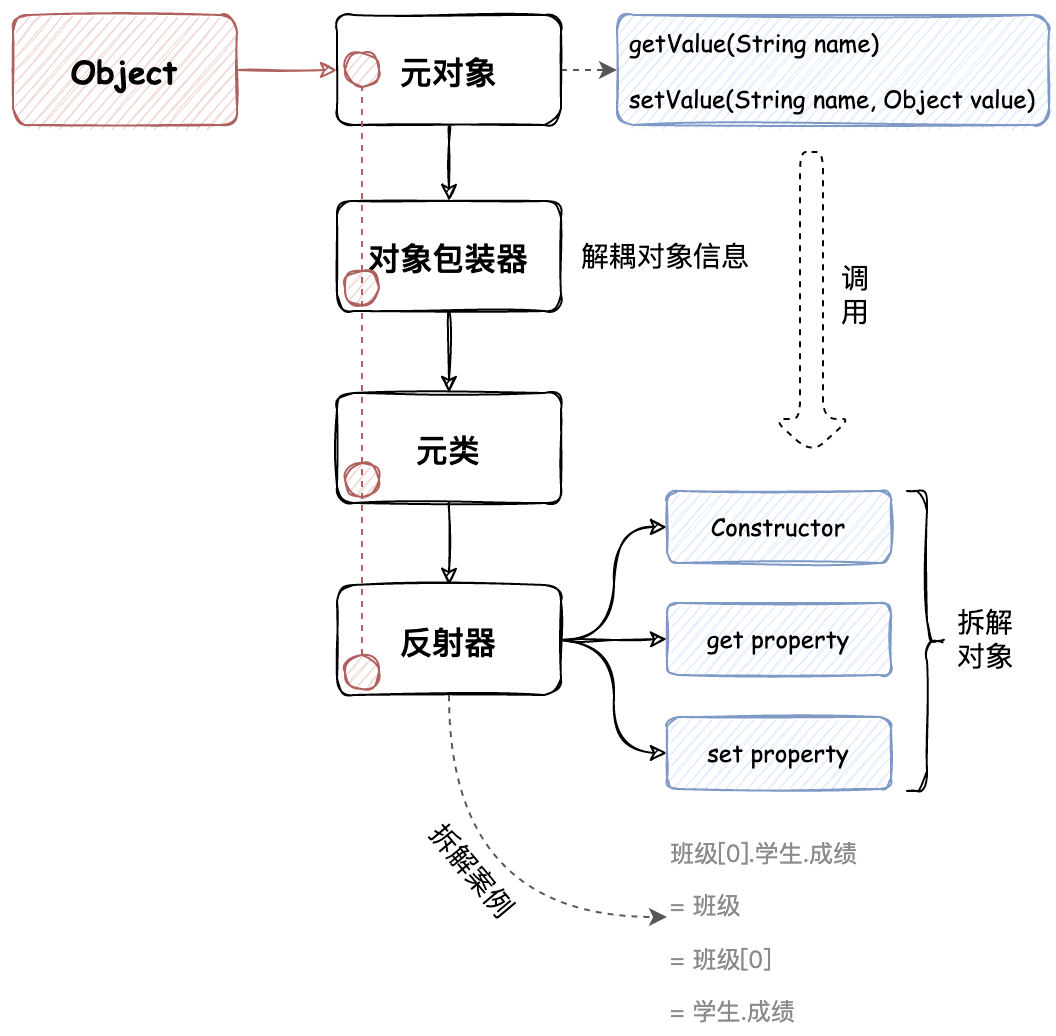
- 其实整个设计过程都以围绕如何拆解对象并提供反射操作为主,那么对于一个对象来说,它所包括的有对象的构造函数、对象的属性、对象的方法。而对象的方法因为都是获取和设置值的操作,所以基本都是get、set处理,所以需要把这些方法在对象拆解的过程中需要摘取出来进行保存。
- 当真正的开始操作时,则会依赖于已经实例化的对象,对其进行属性处理。而这些处理过程实际都是在使用 JDK 所提供的反射进行操作的,而反射过程中的方法名称、入参类型都已经被拆解和处理了,最终使用的时候直接调用即可。
元对象反射工具类,处理对象的属性设置和获取操作核心类:
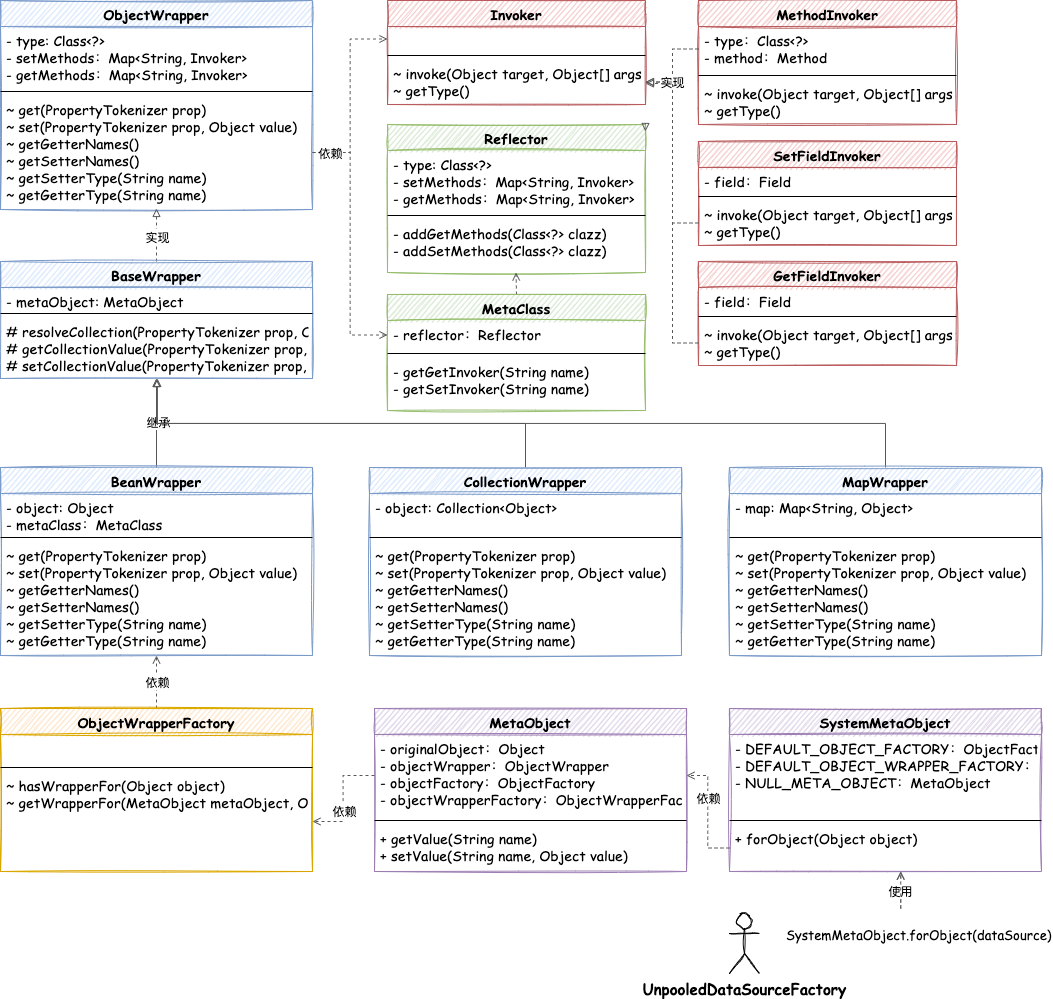
- 以 Reflector 反射器类处理对象类中的 get/set 属性,包装为可调用的 Invoker 反射类,这样在对 get/set 方法反射调用的时候,使用方法名称获取对应的 Invoker 即可
getGetInvoker(String propertyName)。 - 有了反射器的处理,之后就是对原对象的包装了,由 SystemMetaObject 提供创建 MetaObject 元对象的方法,将需要处理的对象进行拆解和
ObjectWrapper对象包装处理。因为一个对象的类型还需要进行一条细节的处理,以及属性信息的拆解,例如:班级[0].学生.成绩这样一个类中的关联类的属性,则需要进行递归的方式拆解处理后,才能设置和获取属性值。 - 最终在 Mybatis 其他的地方就可以,有需要属性值设定时,就可以使用到反射工具包进行处理了。这里首当其冲的会把数据源池化中关于 Properties 属性的处理使用反射工具类进行改造。
反射调用者
关于对象类中的属性值获取和设置可以分为 Field 字段的 get/set 还有普通的 Method 的调用,为了减少使用方的过多的处理,这里可以把集中调用者的实现包装成调用策略,统一接口不同策略不同的实现类。
- 无论任何类型的反射调用,都离不开对象和入参,只要把这两个字段和返回结果定义的通用,就可以包住不同策略的实现类了。
- MethodInvoker
- 提供方法反射调用处理,构造函数会传入对应的方法类型。
- GetFieldInvoker
- getter 方法的调用者处理,因为get是有返回值的,所以直接对 Field 字段操作完后直接返回结果。
- SetFieldInvoker
- setter 方法的调用者处理,因为set是没有返回值的,所以直接对 Field 字段操作完后直接返回 null。
反射器解耦对象
Reflector 反射器专门用于解耦对象信息的,只有把一个对象信息所含带的属性、方法以及关联的类都以此解析出来,才能满足后续对属性值的设置和获取。
- Reflector 反射器类中提供了各类属性、方法、类型以及构造函数的保存操作,当调用反射器时会通过构造函数的处理,逐步从对象类中拆解出这些属性信息,便于后续反射使用。
- 读者在对这部分源码学习时,可以参考对应的类和这里的处理方法,这些方法都是一些对反射的操作,获取出基本的类型、方法信息,并进行整理存放。
元类包装反射器
Reflector 反射器类提供的是最基础的核心功能,很多方法也都是私有的,为了更加方便的使用,还需要做一层元类的包装。在元类 MetaClass 提供必要的创建反射器以及使用反射器获取 get/set 的 Invoker 反射方法。
- MetaClass 元类相当于是对需要处理对象的包装,解耦一个原对象,包装出一个元类。而这些元类、对象包装器以及对象工厂等,再组合出一个元对象。相当于说这些元类和元对象都是对需要操作的原对象解耦后的封装。有了这样的操作,就可以让处理每一个属性或者方法了。
对象包装器Wrapper
对象包装器相当于是更加进一步反射调用包装处理,同时也为不同的对象类型提供不同的包装策略。框架源码都喜欢使用设计模式,从来不是一行行ifelse的代码
在对象包装器接口中定义了更加明确的需要使用的方法,包括定义出了 get/set 标准的通用方法、获取get\set属性名称和属性类型,以及添加属性等操作。
- 对象包装器接口
- 后续所有实现了对象包装器接口的实现类,都需要提供这些方法实现,基本有了这些方法,也就能非常容易的处理一个对象的反射操作了。
- 无论你是设置属性、获取属性、拿到对应的字段列表还是类型都是可以满足的。
元对象封装
在有了反射器、元类、对象包装器以后,在使用对象工厂和包装工厂,就可以组合出一个完整的元对象操作类了。因为所有的不同方式的使用,包括:包装器策略、包装工程、统一的方法处理,这些都需要一个统一的处理方,也就是的元对象进行管理。
- MetaObject 元对象算是整个服务的包装,在构造函数中提供各类对象的包装器类型的创建。之后提供了一些基本的操作封装,这回封装后就更贴近实际的使用了。
- 包括这里提供的 getValue(String name) 、setValue(String name, Object value) 等,其中当一些对象的中的属性信息不是一个层次,是
班级[0].学生.成绩还需要被拆解后才能获取到对应的对象和属性值。 - 当所有的这些内容提供完成以后,就可以使用
SystemMetaObject#forObject提供元对象的获取了。
数据源属性设置
有了实现的属性反射操作工具包,那么对于数据源中属性信息的设置,就可以更加优雅的操作了。
- 在
PooledDataSource#setProperties中,通过MetaObject元对象获取到对应的属性名称,然后通过反射工具包进行属性值的设置,这样就可以把原来的大量的 if-else 代码进行优化了。 - 这样在数据源 UnpooledDataSource、PooledDataSource 中就可以拿到对应的属性值信息了,而不是那种在2个数据源的实现中硬编码操作。
总结
- 关于反射工具类的实现中,使用了大量的 JDK 所提供的关于反射一些处理操作,也包括可以获取一个 Class 类中的属性、字段、方法的信息。那么再有了这些信息以后就可以按照功能流程进行解耦,把属性、反射、包装,都依次拆分出来,并按照设计原则,逐步包装让外接更少的知道内部的处理。
- 通过这样的设计,可以把大量的 if-else 代码进行优化,把大量的硬编码操作进行解耦,让代码更加优雅,也更加容易维护和扩展。
8.细化XML语句构建器,完善静态SQL解析
工程结构:
设计
核心
参照设计原则,对于 XML 信息的读取,各个功能模块的流程上应该符合单一职责,而每一个具体的实现又得具备迪米特法则,这样实现出来的功能才能具有良好的扩展性。通常这类代码也会看着很干净 那么基于这样的诉求,则需要给解析过程中,所属解析的不同内容,按照各自的职责类进行拆解和串联调用。如图:
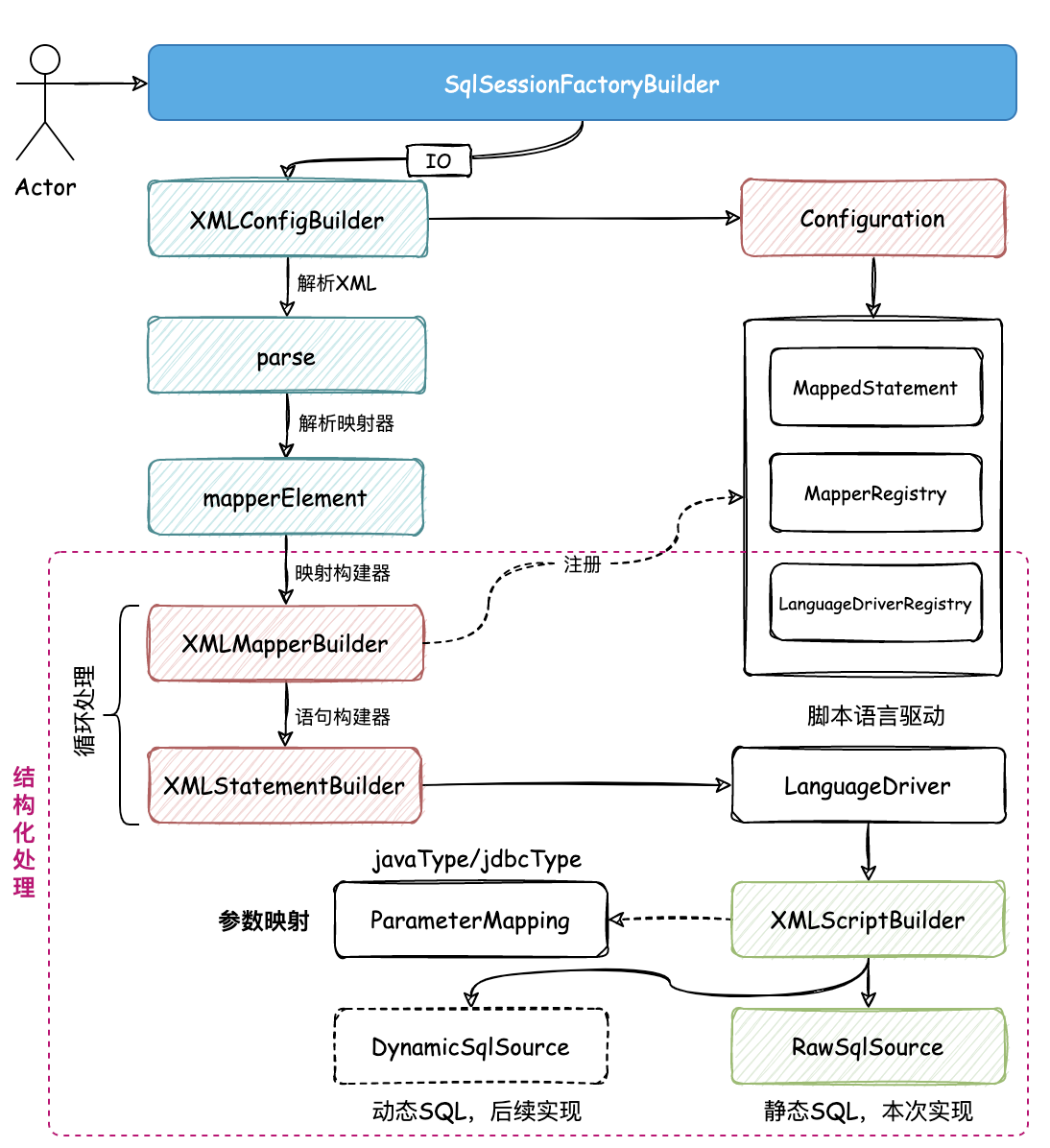
- 与之前的解析代码相对照,不在是把所有的解析都在一个循环中处理,而是在整个解析过程中,引入
XMLMapperBuilder、XMLStatementBuilder分别处理映射构建器和语句构建器,按照不同的职责分别进行解析。 - 与此同时也在语句构建器中,引入脚本语言驱动器,默认实现的是 XML语言驱动器
XMLLanguageDriver,这个类来具体操作静态和动态 SQL 语句节点的解析。这部分的解析处理实现方式很多,即使自己使用正则或者 String 截取也是可以的。所以为了保持与 Mybatis 的统一,直接参照源码 Ognl 的方式进行处理。对应的类是 DynamicContext - 这里所有的解析铺垫,通过解耦的方式实现,都是为了后续在 executor 执行器中,更加方便的处理 setParameters 参数的设置。后面参数的设置,也会涉及到前面实现的元对象反射工具类的使用。
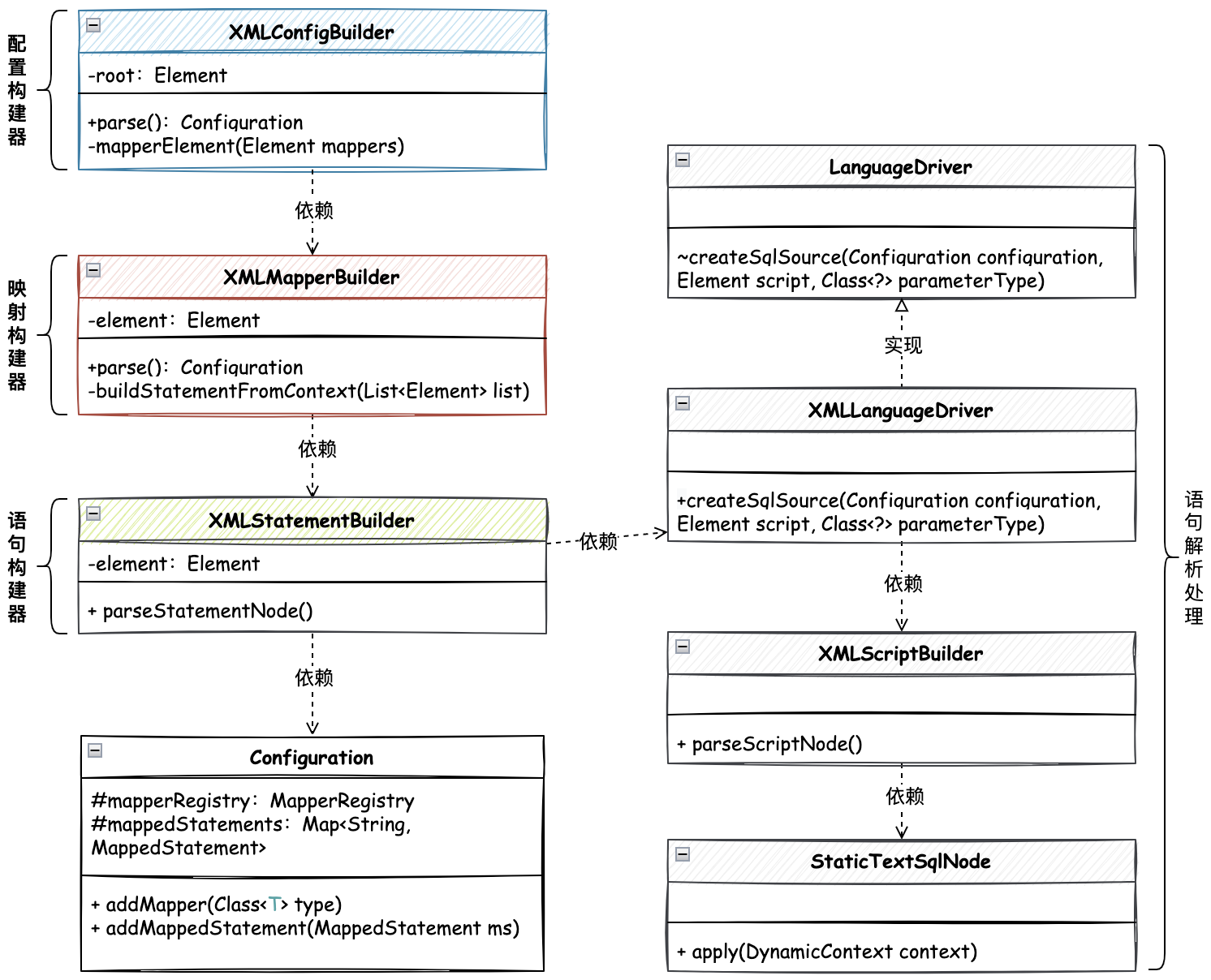
XML 语句解析构建器,核心逻辑类关系,如图:
解耦映射解析
提供单独的 XML 映射构建器 XMLMapperBuilder 类,把关于 Mapper 内的 SQL 进行解析处理。提供了这个类以后,就可以把这个类的操作放到 XML 配置构建器,XMLConfigBuilder#mapperElement 中进行使用了。
在 XMLMapperBuilder#parse 的解析中,主要体现在资源解析判断、Mapper解析和绑定映射器到
- configuration.isResourceLoaded 资源判断避免重复解析,做了个记录。
- configuration.addMapper 绑定映射器主要是把 namespace dao.IUserDao 绑定到 Mapper 上。也就是注册到映射器注册机里。
- configurationElement 方法调用的
buildStatementFromContext,重在处理 XML 语句构建器。 - 在 XMLConfigBuilder#mapperElement 中,把原来流程化的处理进行解耦,调用
XMLMapperBuilder#parse方法进行解析处理。
语句构建器
XMLStatementBuilder 语句构建器主要解析 XML 中 select|insert|update|delete 中的语句。这里的解析过程中,主要是对 SQL 语句的解析,包括静态 SQL 和动态 SQL 的解析。这里的解析过程中,主要是对 SQL 语句的解析,包括静态 SQL 和动态 SQL 的解析。
源码详见:step8.mybatis.builder.xml.XMLStatementBuilder
- 整个这部分内容的解析,就是从 XMLConfigBuilder 拆解出来关于 Mapper 语句解析的部分,通过这样这样的解耦设计,会让整个流程更加清晰。
- XMLStatementBuilder#parseStatementNode 方法是解析 SQL 语句节点的过程,包括了语句的ID、参数类型、结果类型、命令(select|insert|update|delete),以及使用语言驱动器处理和封装SQL信息,当解析完成后写入到 Configuration 配置文件中的 Map<String, MappedStatement> 映射语句存放中。
脚本语言驱动
在 XMLStatementBuilder#parseStatementNode 语句构建器的解析中,可以看到这么一块,获取默认语言驱动器并解析SQL的操作。其实这部分就是 XML 脚步语言驱动器所实现的功能,在 XMLScriptBuilder 中处理静态SQL和动态SQL,不过目前只是实现了其中的一部分,待后续这部分框架都完善后在进行扩展,避免一次引入过多的代码。
- 定义接口
- 源码详见:
step8.mybatis.scripting.LanguageDriver - 定义脚本语言驱动接口,提供创建 SQL 信息的方法,入参包括了配置、元素、参数。其实它的实现类一共有3个;
XMLLanguageDriver、RawLanguageDriver、VelocityLanguageDriver,这里只是实现了默认的第一个即可。
- 源码详见:
- XML语言驱动器实现
- 源码详见:
step8.mybatis.scripting.xmltags.XMLLanguageDriver - 关于 XML 语言驱动器的实现比较简单,只是封装了对 XMLScriptBuilder 的调用处理。
- 源码详见:
- XML脚本构建器解析
- 源码详见:
step8.mybatis.scripting.xmltags.XMLScriptBuilder - XMLScriptBuilder#parseScriptNode 解析SQL节点的处理其实没有太多复杂的内容,主要是对 RawSqlSource 的包装处理。
- 源码详见:
- SQL源码构建器
- 源码详见:
step8.mybatis.builder.SqlSourceBuilder - 关于 BoundSql.parameterMappings 的参数就是来自于 ParameterMappingTokenHandler#buildParameterMapping 方法进行构建处理的。
- 具体的 javaType、jdbcType 会体现到 ParameterExpression 参数表达式中完成解析操作。
- 源码详见:
DefaultSqlSession 调用调整
因为以上整个设计和实现,调整了解析过程,以及细化了 SQL 的创建。那么在 MappedStatement 映射语句中,则使用 SqlSource 替换了 BoundSql,所以在 DefaultSqlSession 中也会有相应的调整。
- 源码详见:
step8.mybatis.session.defaults.DefaultSqlSession - 这里的使用调整也不大,主要体现在获取SQL的操作;
ms.getSqlSource().getBoundSql(parameter)这样获取后,后面的流程就没有多少变化了。
总结
- 把原本 CRUD 的代码,通过设计原则进行拆分和解耦,运用不用的类来承担不同的职责,完整整个功能的实现。这包括;映射构建器、语句构建器、源码构建器的综合使用,以及对应的引用;脚本语言驱动和脚本构建器解析,处理的 XML 中的 SQL 语句。
- 通过这样的重构代码,也能让对平常的业务开发中的大片面向过程的流程代码有所感悟,当你可以细分拆解职责功能到不同的类中去以后,你的代码会更加的清晰并易于维护。
- 续将继续按照现在的扩展结构底座,完成其他模块的功能逻辑开发,因为了这些基础内容的建造,再继续补充功能也会更加容易。
9.使用策略模式,调用参数处理器
工程结构:
设计
核心
自动化解析 XML 中 SQL 拆分出所有的参数类型后,则应该根据不同的参数进行不同的类型设置,也就;Long 调用 ps.setLong、String 调用 ps.setString 所以这里需要使用策略模式,在解析 SQL 时按照不同的执行策略,封装进去类型处理器(也就是是实现 TypeHandler 接口的过程)。如图:
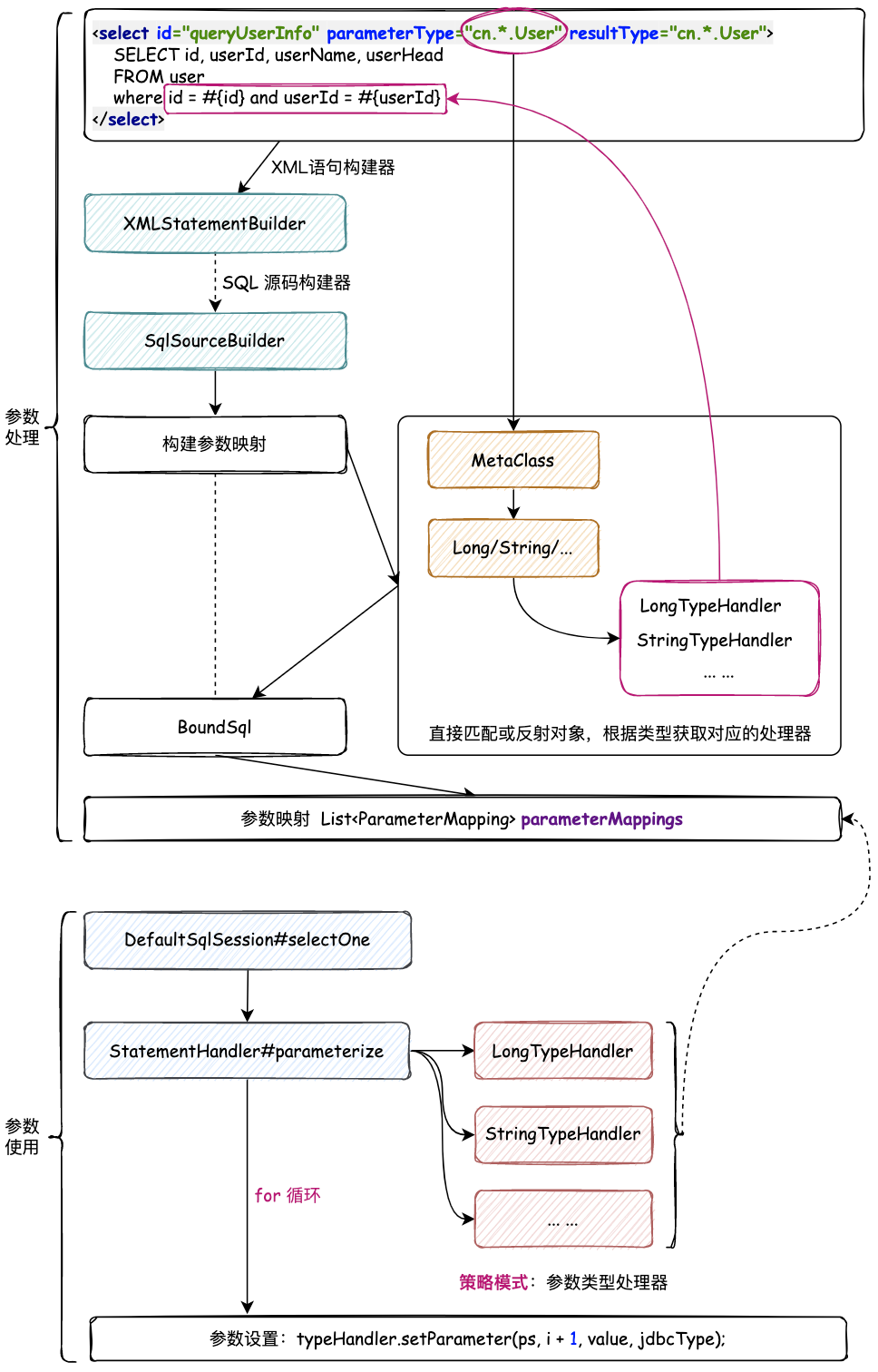
- 在解析 SQL 语句时,按照不同的参数类型,封装进去类型处理器(也就是是实现 TypeHandler 接口的过程)。
- 关于参数的处理,因为有很多的类型(
Long\String\Object\...),所以这里最重要的体现则是策略模式的使用。 - 这里包括了构建参数时根据类型,选择对应的策略类型处理器,填充到参数映射集合中。另外一方面是参数的使用,也就是在执行
DefaultSqlSession#selectOne的链路中,包括了参数的设置,按照参数的不同类型,获取出对应的处理器,以及入参值。
使用策略模式,处理参数处理器核心类关系,如图:
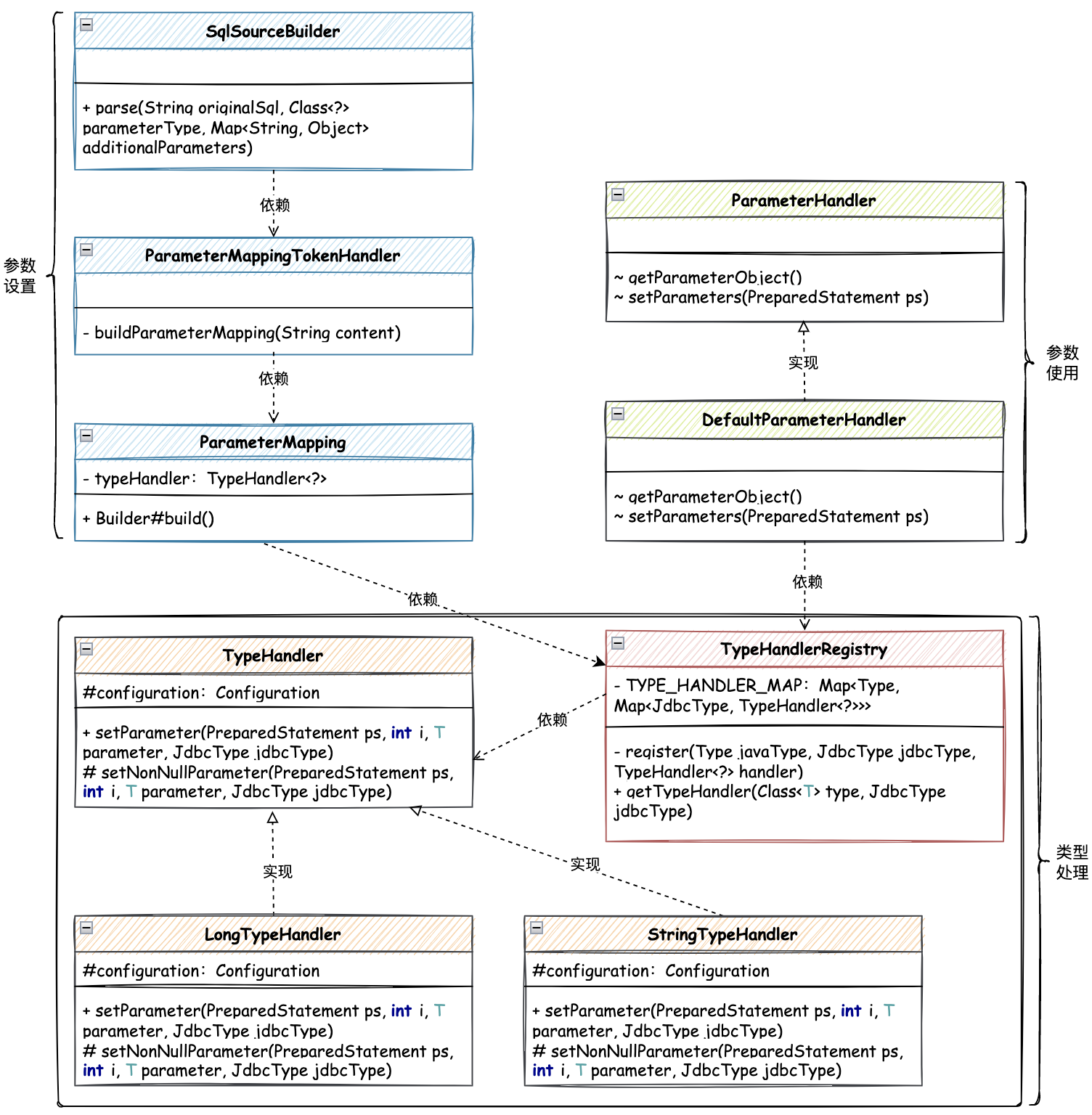
核心处理主要分为三块;类型处理、参数设置、参数使用;
- 以定义
TypeHandler类型处理器策略接口,实现不同的处理策略,包括;Long、String、Integer 等。这里先只实现2种类型,读者在学习过程中,可以按照这个结构来添加其他类型。 - 类型策略处理器实现完成后,需要注册到处理器注册机中,后续其他模块参数的设置还是使用都是从 Configuration 中获取到
TypeHandlerRegistry进行使用。 - 那么有了这样的策略处理器以后,在进行操作解析
SQL的时候,就可以按照不同的类型把对应的策略处理器设置到BoundSql#parameterMappings参数里,后续使用也是从这里进行获取。
入参数校准
- 源码详见:
step9.mybatis.binding.MapperMethod - 在映射器方法中
MapperMethod#execute将原来的直接将参数 args 传递给SqlSession#selectOne方法,调整为转换后再传递对象。 - 其实这里的转换操作就是来自于
Method#getParameterTypes对参数的获取和处理,与 args 进行比对。如果是单个参数,则直接返回参数 Tree 树结构下的对应节点值。非单个类型,则需要进行循环处理,这样转换后的参数才能被直接使用。
参数策略处理器
在 Mybatis 的源码包中,有一个 type 包,这个包下所提供的就是一套参数的处理策略集合。它通过定义类型处理器接口、由抽象模板实现并定义标准流程,定提取抽象方法交给子类实现,这些子类就是各个类型处理器的具体实现。
- 策略接口
- 源码详见:
step9.mybatis.type.TypeHandler - 首先定义一个类型处理器的接口,这和在日常的业务开发中是类似的,就像如果是发货商品,则定义一个统一标准接口,之后根据这个接口实现出不同的发货策略。
- 这里设置参数也是一样,所有不同类型的参数,都可以被提取出来这些标准的参数字段和异常,后续的子类按照这个标准实现即可。
- 源码详见:
- 模板模式
- 源码详见:
step9.mybatis.type.BaseTypeHandler - 通过抽象基类的流程模板定义,便于一些参数的判断和处理。不过目前还不需要那么多的流程校验,所以这里只是定义和调用了一个最基本的抽象方法 setNonNullParameter。
- 不过有一个这样的结构,可以让大家更加清楚整个 Mybatis 源码的框架,便于后续阅读或者扩展此部分源码的时候,有一个框架结构的认知。
- 子类实现
- 源码详见:
step9.mybatis.type.* - 这里的接口实现举了个例子,分别是;LongTypeHandler、StringTypeHandler,在 Mybatis 源码中还有很多其他类型,这里暂时不需要实现那么多。
- 源码详见:
- 类型注册机
- 类型处理器注册机
TypeHandlerRegistry是前面实现的,这里只需要在这个类结构下,注册新的类型就可以了。 - 源码详见:
step9.mybatis.type.TypeHandlerRegistry - 这里在构造函数中,新增加了 LongTypeHandler、StringTypeHandler 两种类型的注册器。
- 同时可以注意到,无论是对象类型,还是基本类型,都是一个类型处理器。只不过在注册的时候多注册了一个。这样在后续的使用中,就可以按照类型直接获取到对应的处理器了。
- 类型处理器注册机
参数构建
- 源码详见:
step9.mybatis.builder.SqlSourceBuilder - 这一部分就是对参数的细化处理,构建出参数的映射关系,首先是 if 判断对应的参数类型是否在 TypeHandlerRegistry 注册器中,如果不在则拆解对象,按属性进行获取 propertyType 的操作。
- 这一块也用到了 MetaClass 反射工具类的使用,它的存在可以让更加方便的处理,否则还需要要再写反射类进行获取对象属性操作。
参数使用
参数构建完成后,就可以在 DefaultSqlSession#selectOne 调用时设置参数使用了。那么这里的链路关系;Executor#query - > SimpleExecutor#doQuery -> StatementHandler#parameterize -> PreparedStatementHandler#parameterize -> ParameterHandler#setParameters 到了 ParameterHandler#setParameters 就可以看到了根据参数的不同处理器循环设置参数。
- 源码详见:
step9.mybatis.executor.parameter.DefaultParameterHandler - 每一个循环的参数设置,都是从 BoundSql 中获取 ParameterMapping 集合进行循环操作,而这个集合参数就是前面 ParameterMappingTokenHandler#buildParameterMapping 构建参数映射时处理的。
- 设置参数时根据参数的 parameterObject 入参的信息,判断是否基本类型,如果不是则从对象中进行拆解获取(也就是一个对象A中包括属性b),处理完成后就可以准确拿到对应的入参值了。因为在映射器方法 MapperMethod 中已经处理了一遍方法签名,所以这里的入参就更方便使用了。
- 基本信息获取完成后,则根据参数类型获取到对应的 TypeHandler 类型处理器,也就是找到 LongTypeHandler、StringTypeHandler 等,确定找到以后,则可以进行对应的参数设置了 typeHandler.setParameter(ps, i + 1, value, jdbcType) 通过这样的方式把之前硬编码的操作进行解耦。
总结
- 通过这样的设计,可以把原本硬编码的参数设置,按照不同的类型进行解耦,使用策略模式,把不同的类型处理器注册到注册机中,然后在使用时,根据参数类型获取到对应的处理器,最后进行参数的设置。
- 比较重要的体现是关于参数类型的策略化设计,通过策略解耦,模板定义流程,让整个参数设置变得更加清晰,也就不需要硬编码了。
- 除此之外也有一些细节的功能点,如;MapperMethod 中添加方法签名、类型处理器创建和使用时候,都使用了 MetaObject 这样的反射器工具类进行处理。
10.流程解耦,封装结果集处理器
工程结构:
设计:
核心
在使用 JDBC 获取到查询结果 ResultSet#getObject 可以获取返回属性值,但其实 ResultSet 是可以按照不同的属性类型进行返回结果的,而不是都返回 Object 对象。那么其实在上一章节中处理属性信息时候,所开发的 TypeHandler 接口的实现类,就可以扩充返回结果的方法,例如:LongTypeHandler#getResult、StringTypeHandler#getResult 等,这样就可以使用策略模式非常明确的定位到返回的结果,而不需要进行if判断处理。
再有了这个目标的前提下,就可以通过解析 XML 信息时封装返回类型到映射器语句类中,MappedStatement#resultMaps 直到执行完 SQL 语句,按照的返回结果参数类型,创建对象和使用 MetaObject 反射工具类填充属性信息。如图:
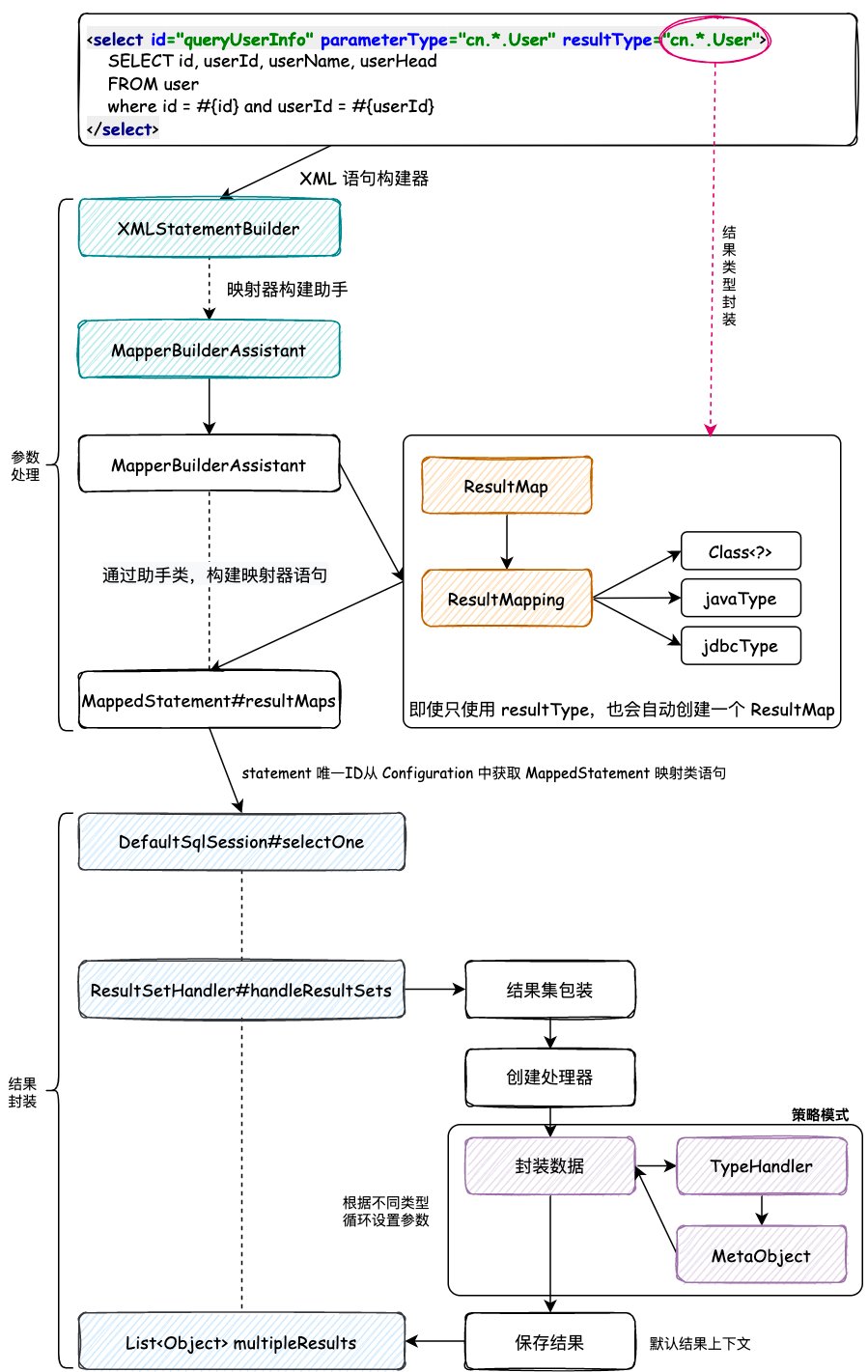
- 首先在解析 XML 语句解析构建器中,添加一个 MapperBuilderAssistant 映射器的助手类,方便对参数的统一包装处理,按照职责归属的方式进行细分解耦。通过这样的方式在 MapperBuilderAssistant#setStatementResultMap 中封装返回结果信息,一般来说使用 Mybatis 配置返回对象的时候 ResultType 就能解决大部分问题,而不需要都是配置一个 ResultMap 映射结果。但这里的设计其实是把 ResultType 也按照一个 ResultMap 的方式进行封装处理,这样统一一个标准的方式进行包装,做了到适配的效果,也更加方便后面对这样的参数进行统一使用。
- 接下来就是执行 JDBC 操作查询到数据以后,对结果的封装。那么在 DefaultResultSetHandler 返回结果处理中,首先会按照已经解析的到的 ResultType 进行对象的实例化。实例化对象以后再根据解析出来对象中参数的名称获取对应的类型,在根据类型找到 TypeHandler 接口实现类,也就是前面提到的 LongTypeHandler、StringTypeHandler,因为通过这样的方式,可以避免 if···else 的判断,而是直接O(1)时间复杂度定位到对应的类型处理器,在不同的类型处理器中返回结果信息。最终拿到结果再通过前面章节已经开发过的 MetaObject 反射工具类进行属性信息的设置。metaObject.setValue(property, value) 最终填充实例化并设置了属性内容的结果对象到上下文中,直至处理完成返回最终的结果数据,以此处理完成。
出参参数处理
鉴于对 XML 语句构建器中解析语句后的信息封装会逐步增多,所以这里需要引入映射构建器助手对类中方法的职责进行划分,降低一个方法块内的逻辑复杂度。这样的方式也更加利于代码的维护和扩展。
- 结果映射封装
- 熟悉使用 Mybatis 的读者都清楚的知道,在一条语句配置中需要有包括一个返回类型的配置,这个返回类型可以是通过 resultType 配置,也可以使用 resultMap 进行处理,而无论使用哪种方式其实最终都会被封装成统一的 ResultMap 结果映射类。
- 那么一般配置 ResultMap 都是配置了字段的映射,所以实际的代码开发中 ResultMap 还会包含 ResultMapping 也就是每一个字段的映射信息,包括:colum、javaType、jdbcType 等。由于暂时还不涉及到 ResultMap 的使用,所以这里先只是建好基本的地基结构就可以。
- 源码详见:
step10.mybatis.mapping.ResultMap- ResultMap 就是一个简单的返回结果信息映射类,并提供了建造者方法,方便外部使用。没有太多的逻辑行为,具体可以参照源码。
- 构建器助手
- MapperBuilderAssistant 构建器助手专门为创建 MappedStatement 映射语句类而服务的,在这个类中封装了入参和出参的映射、以及把这些配置信息写入到 Configuration 配置项中。
- 源码详见:
step10.mybatis.builder.MapperBuilderAssistant- 在映射构建器助手中,提供了添加映射器语句的方法,在这个方法中更加标准的封装了入参和出参信息。如果这些内容全部都堆砌到 XMLStatementBuilder 语句构建器的解析中,就会显得非常臃肿不易于维护了
- 在 MapperBuilderAssistant#setStatementResultMap 方法中,其实它只是一个非常简单的结果映射建造的过程,无论是否为 ResultMap 都会进行这样的封装处理。并最终把创建的信息写入到 MappedStatement 映射语句类中。
- 调用助手类
- 接下来就可以清理 XMLStatementBuilder 语句构建器中解析后,映射语句类的构建和存放处理流程。通过使用助手类,统一封装参数信息。
- 源码详见:
step10.mybatis.builder.xml.XMLStatementBuilder- 与之前相比,对于这部分的解析后的结果处理的职责内容,划分到了新增加的助手类中,这种实现方式在 Mybatis 的源码中还是非常多的,大部分的内容处理,都会提供一个助手类进行操作。
查询结果封装
从 DefaultSqlSession 调用 Executor 语句执行器,一直到 PreparedStatementHandler 预处理语句处理,最后就是 DefaultResultSetHandler 结果信息的封装。
前面章节对此处的封装处理,并没有解耦的操作,只是简单的 JDBC 使用通过查询结果,反射处理返回信息就结束了。如果是使用这样的一个简单的 if···else 面向过程方式进行开发,那么后续所需要满足 Mybatis 的全部封装对象功能,就会变得特别吃力,一个方法块也会越来越大。
所以这一部分的内容处理是需要被解耦,分为;对象的实例化、结果信息的封装、策略模式的处理、写入上下文返回等操作,只有通过这样的解耦流程,才能更加方便的扩展流程不同节点中的各类需求。
- 源码详见:
step10.mybatis.executor.resultset.DefaultResultSetHandler#handleResultSet- 这是一套结果封装的核心处理流程,包括创建处理器、封装数据和保存结果,接下来就分别介绍下这块代码的具体实现。
- 结果集收集器
- 源码详见:
step10.mybatis.executor.result.DefaultResultHandler- 这里封装了一个非常简单的结果集对象,默认情况下都会写入到这个对象的 list 集合中。
- 源码详见:
- 对象创建
- 在处理封装数据的过程中,包括根据 resultType 使用反射工具类 ObjectFactory#create 方法创建出 Bean 对象。这个过程会根据不同的类型进行创建。
- 源码详见:
step10.mybatis.executor.resultset.DefaultResultSetHandler#createResultObject- 对于这样的普通对象,只需要使用反射工具类就可以实例化对象了,不过这个时候属性信息还没有填充。其实和使用的 clazz.newInstance(); 也是一样的效果
- 属性填充
- 对象实例化完成后,就是根据 ResultSet 获取出对应的值填充到对象的属性中,但这里需要注意,这个结果的获取来自于 TypeHandler#getResult 接口新增的方法,由不同的类型处理器实现,通过这样的策略模式设计方式就可以巧妙的避免 if···else 的判断处理。
- 源码详见:
step10.mybatis.executor.resultset.DefaultResultSetHandler#applyAutomaticMappings- columnName 是属性名称,根据属性名称,按照反射工具类从对象中获取对应的 properyType 属性类型,之后再根据类型获取到 TypeHandler 类型处理器。有了具体的类型处理器,在获取每一个类型处理器下的结果内容就更加方便了。
- 获取属性值后,再使用 MetaObject 反射工具类设置属性值,一次循环设置完成以后,这样一个完整的结果信息 Bean 对象就可以返回了。返回后写入到 DefaultResultContext#nextResultObject 上下文中
总结
- 这次的整个功能实现,都在围绕流程的解耦进行处理,将对象的参数解析和结果封装都进行拆解,通过这样的方式来分配各个模块的单一职责,不让一个类的方法承担过多的交叉功能。
- 那么在结合这样的思想和设计,反复阅读和动手实践中,来学习这样的代码设计和开发过程,都能为以后实际开发业务代码时候带来参考建议,避免总是把所有的流程都写到一个类或者方法中。
11.完善ORM框架增删改查
工程结构:
设计
核心
假定这就是你正在承接的业务功能需求,你要在现在有的框架中完成对 insert/update/delete 方法的扩展。那么这个时候你需要思考,哪里是这个流程的开始,之后从流程的开始进行梳理。
那么这里显而易见,我们需要首先解决的是对 XML 的解析,由于之前在 ORM 框架的开发中,仅是处理了 select 的 SQL 信息,现在则需要把 insert/update/delete 的语句也按照解析 select 的方式进行处理。
在添加了解析新类型 SQL 操作前提下,后续 DefaultSqlSession 中新增的执行 SQL 方法 insert/update/delete 就可以通过 Configuration 配置项拿到对应的映射器语句,并执行后续的处理流程。具体设计,如图:
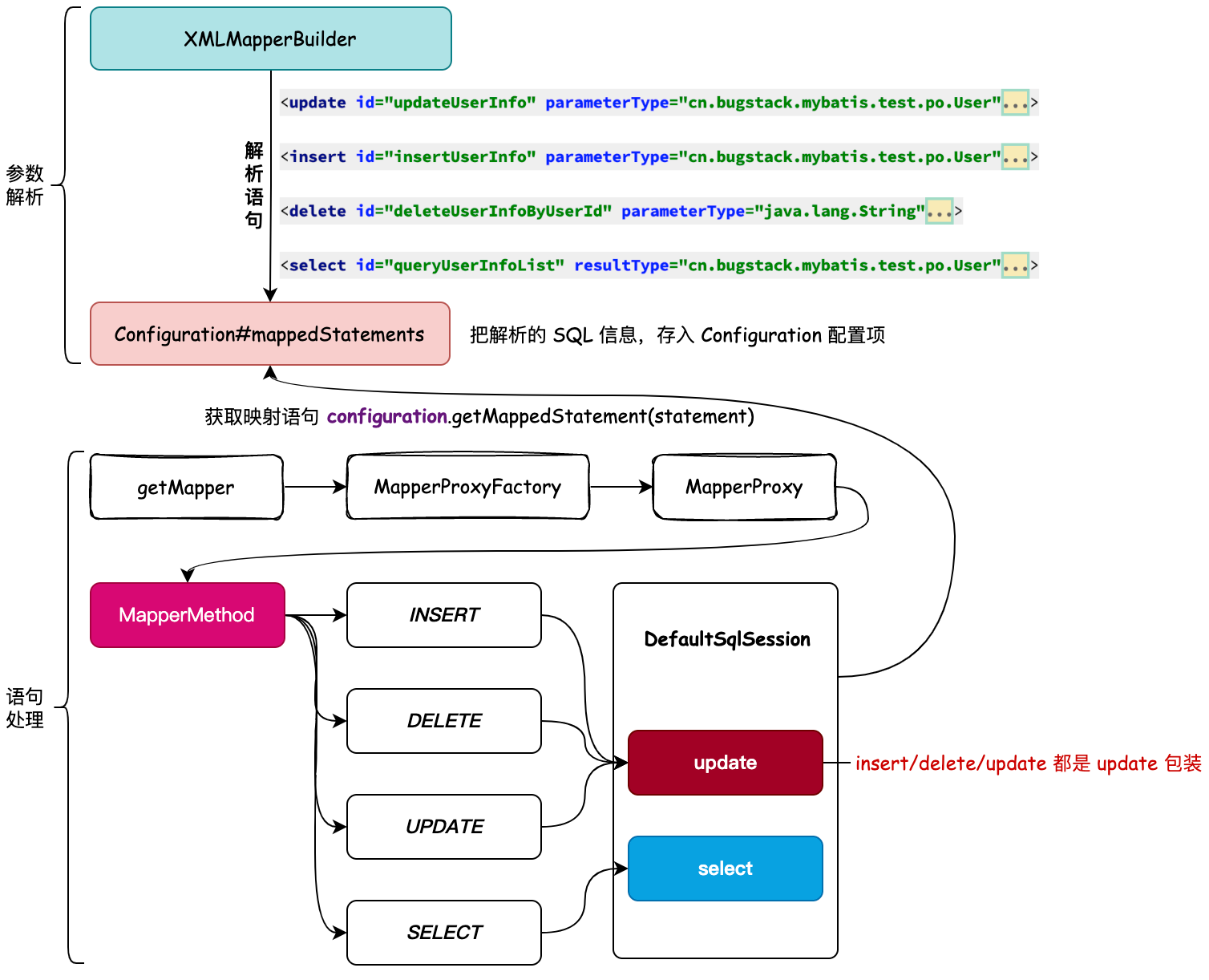
- 在执行
sqlSession.getMapper(IUserDao.class)获取 Mapper 以后,后续的流程会依次串联到映射器工厂、映射器,以及获取对应的映射器方法,从 MapperMethod 映射器方法开始,调用的就是 DefaultSqlSession 了。 - 那么这里要注意,除了我们已经开发完的
DefaultSqlSession#select方法,其他定义的 insert、delete、update,都是调用内部的 update 方法,这也是 Mybatis ORM 框架对此类语句处理的一个包装。因为除了 select 方法,insert、delete、update,都是共性处理逻辑,所以可以被包装成一个逻辑来处理。
完善ORM框架,增删改查操作核心类关系,如图:
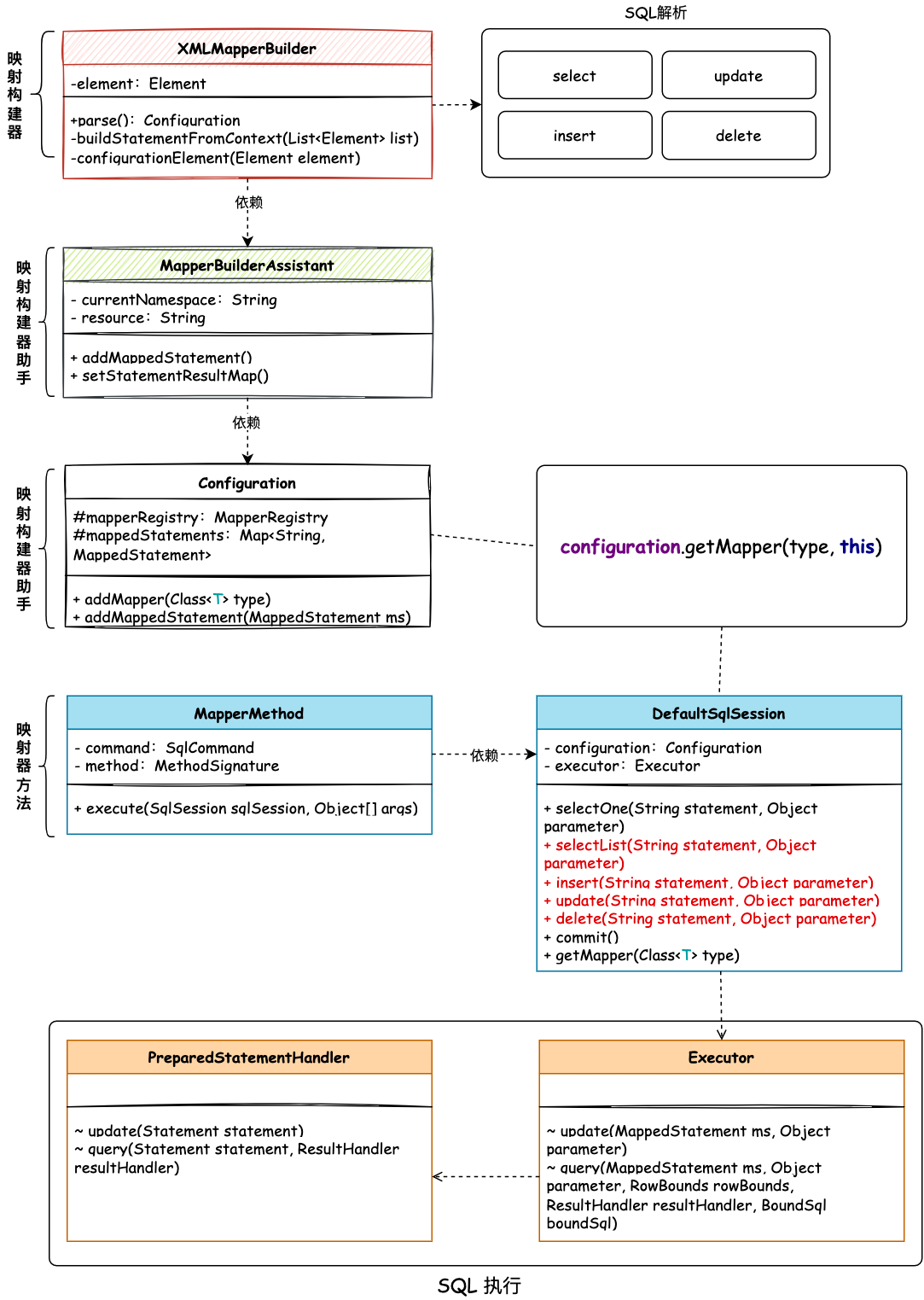
- 首先在 XML 映射器构建器中,扩展
XMLMapperBuilder#configurationElement方法,添加对insert/update/delete的解析操作。这部分不需要太多的处理,只要添加上解析类型,就能满足当前章节的诉求。同样这里的解析信息都会存放到Configuration配置项的映射语句Map集合mappedStatements中,供后续DefaultSqlSession执行SQL获取配置信息时使用。 - 接下来是对 MapperMethod 映射器方法的改造,在前面章节我们只是处理了 MapperMethod#execute 中 SELECT 类型的语句,这一章节需要在这里扩展
INSERT、DELETE、UPDATE,同时还需要对 SELECT 进行扩展查询出多个结果集的方法。 - 所需要扩展的这些信息,都是有
DefaultSqlSession调用执行器Executor进行处理的,这里你会看到 Executor 中只有 update 这个新增方法,并没有insert、delete,因为这两个方法也是调用的 update 进行处理的。 - 以上这些内容实现完成后,所有新增方法的调用,都会按照前面章节实现的语句执行、参数处理、结果封装等步骤,把流程执行完毕,并返回最终的结果。
扩展解析元素
首先我们需要先解决新增 SQL 类型的 XML 语句,把 insert、update、delete,几种类型的 SQL 解析完成后,存放到 Configuration 配置项的映射器语句中。
- 源码详见:
step11.mybatis.builder.xml.XMLMapperBuilder- 与前面相比,这里改造 buildStatementFromContext 方法的入参类型为 list 的集合,也就是处理所传递到方法中的所有语句的集合。
- 之后在 XMLMapperBuilder#configurationElement 调用层,传递
element.elements("select")、element.elements("insert")、element.elements("update")、element.elements("delete")四个类型的方法,就可以把配置到 Mapper XML 中的不同 SQL 解析存放起来了。
新增执行方法
在 Mybatis 的 ORM 框架中,DefaultSqlSession 中最终的 SQL 执行都会调用到 Executor 执行器的,所以这里我们先来看下关于执行器中新增方法的变化。
- update接口定义
- 源码详见:
step11.mybatis.executor.Executor- update 是 Executor 执行接口新增的方法,在这次功能扩展中,Executor 执行器也就只增加了这么一个 update 方法。因为其他两个方法 insert、delete 的调用,也都是调用 update 就够了,所以这里 Mybatis 并没有在执行器中定义新的方法。
- 源码详见:
- update接口实现
- 源码详见:
step11.mybatis.executor.SimpleExecutor- 在 SimpleExecutor 简单执行器中,新增加了 update 方法的实现,这里的实现其实就是调用 doUpdate 方法,这个方法中会根据不同的 SQL 类型,调用不同的方法进行处理。
- SimpleExecutor#doUpdate 方法是 BaseExecutor 抽象类实现 Executor#update 接口后,定义的抽象方法。
- 这个抽象方法中,和 doQuery 方法几乎类似,都是创建一个新的 StatementHandler 语句处理器,之后准备语句,执行处理。
- 但这里有一点需要注意,doUpdate 创建 StatementHandler 语句处理器的时候,是没有 resultHandler、boundSql 两个参数的,所以在创建的过程中,是需要对有必要使用的 boundSql 进行判断处理的。这部分内容主要体现在 BaseStatementHandler 的构造函数中,关于 boundSql 的判断和实例化处理
- 源码详见:
- 语句处理器实现
- 语句处理器的实现,主要变化在 BaseStatementHandler 的构造函数中添加了 boundSql 的初始化
- 因为只有获取了 BoundSql 的参数,才能方便的执行后续对 SQL 处理的操作。所以在执行 update 方法,没有传入 BoundSql 的时候,则需要这里进行判断以及自己获取的处理操作。接下来是对抽象类的实现,具体的处理 update 方法。
- 源码详见:
step11.mybatis.executor.statement.PreparedStatementHandler- 在 PreparedStatementHandler 预处理语句处理器中,实现了 update 方法,相对于 query 方法的实现,其实只是相当于 JDBC 操作数据库返回结果集的变化,update 处理要返回 SQL 的操作影响了多少条数据的数量。
SqlSession 定义和实现CRUD接口
在 SqlSession 中需要新增出处理数据库的接口,包括:selectList、insert、update、delete,这里我们来看下 DefaultSqlSession 对 SqlSession 接口方法的具体实现。
源码详见:step11.mybatis.session.defaults.DefaultSqlSession
- 在 DefaultSqlSession 的具体实现中可以看到,update 方法调用了具体的执行器封装成方法以后,insert、delete 都是调用的这个 update 方法进行操作的。接口定义的是单一执行,接口实现是做了适配封装
- 另外这里单独提供了 selectList 方法,所以把之前在 selectOne 关于 executor.query 的执行处理,都迁移到 selectList 方法中。之后在 selectOne 中调用 selectList 方法,并给出相应的判断处理。
映射器命令执行调度
以上这些所实现的语句执行器、SqlSession 包装,最终都会交给 MapperMethod 映射器方法根据不同的 SQL 命令调用不同的 SqlSession 方法进行执行。
- 映射器方法 MapperMethod#execute 会根据不同的 SqlCommand 指令调用到不同的方法上去,INSERT、DELETE、UPDATE 分别按照对应的方法调用即可。这里 SELECT 进行了扩展,因为需要按照不同的方法出参类型,调用不同的方法,主要是 selectList、selectOne 的区别。
- 另外这里 method.returnsMany 来自于 MapperMethod.MethodSignature 方法签名中进行通过,返回类型进行获取的
- 源码详见:
step11.mybatis.binding.MapperMethod
总结
- 到此为止就把 Mybatis 的全部主干流程串联实现完成了,可以执行对数据库的增删改查操作,读者伙伴也可以发现,本章节在原有的内容下,进行扩展的时候也是非常方便的,甚至不要多大的代码改动。这主要也得益于框架在设计实现过程中,合理运用设计原则和设计模式的好处。
- 在学习的过程中,可以调试源码中的一些参数,比如像事务是否自动提交,查询出来的参数是否可以添加其他类型,在增删改查中,是否还有其他情况的处理。
12.通过注解配置执行SQL语句
工程结构

设计
核心
关于引入注解方式处理 SQL 的配置,在设计上主要在于将注解的解析部分与 Mapper XML 进行策略处理,对于不同类型的使用方式,做到解析结果一致,那么后续的处理 SQL 执行和结果封装等流程就可以正常执行了。
这一部分的代码逻辑变动,主要以 XMLConfigBuilder 配置构建器的 Mapper 解析开始,因为只有从这里开始才是判断一个 Mapper 到底是使用了 XML 配置还是注解配置。
基于这样不同的 mapper 引入的类型信息,则需要在 XMLConfigBuilder 配置构建器,解析 Mapper 元素信息时进行判断出来,按照不同的获取类型,resource、class 进行不同的解析处理。只要在解析处理中把这两部分的差异做适配处理,最终后续的流程也就可以正常进行了。如图:
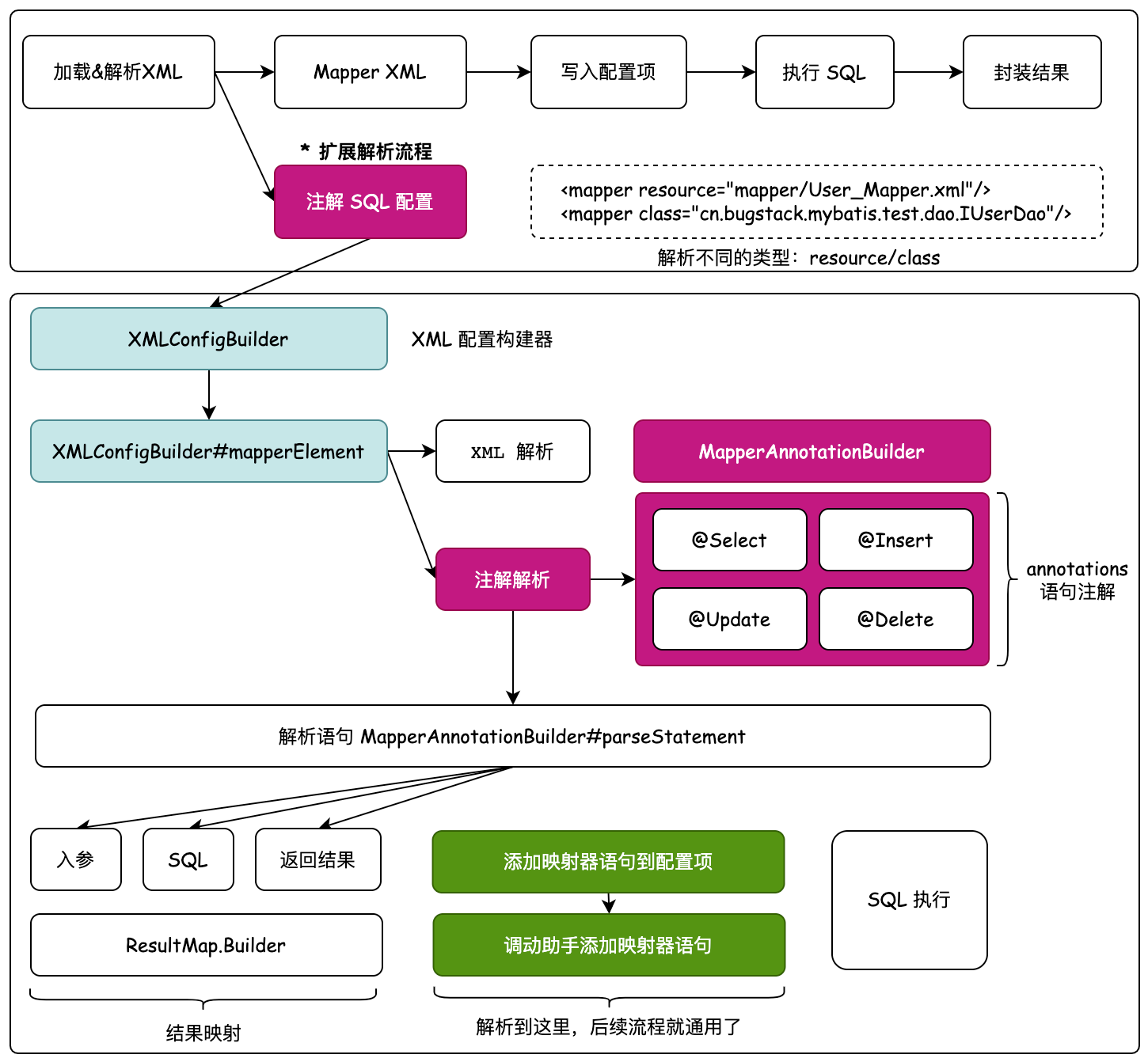
在设计上首先以加载解析 XML 为入口,处理不同配置 SQL 方式的解析操作,那么这里就是结合原有解析 Mapper XML 配置扩展注解 SQL 配置方式。
具体的处理过程主要在 XMLConfigBuilder#mapperElement 配置构建器解析 mapper 配置时,处理关于注解的解析部分。这些注解目前添加了 @Select、@Insert、@Update、@Delete,处理解析注解则会向 Configuration 配置项中添加 ResultMap、MappedStatement 信息,用于后续获取 Mapper 调用 DefaultSqlSession 对应的执行方法时,拿到映射器语句配置进行 SQL 执行和结果封装。
从前到后的处理过程中可以看到,只要把解析部分做策略处理,后续的执行流程是保持一致的。接下来我们就看下代码中的实现细节。
通过注解配置执行SQL语句核心类关系,如图:
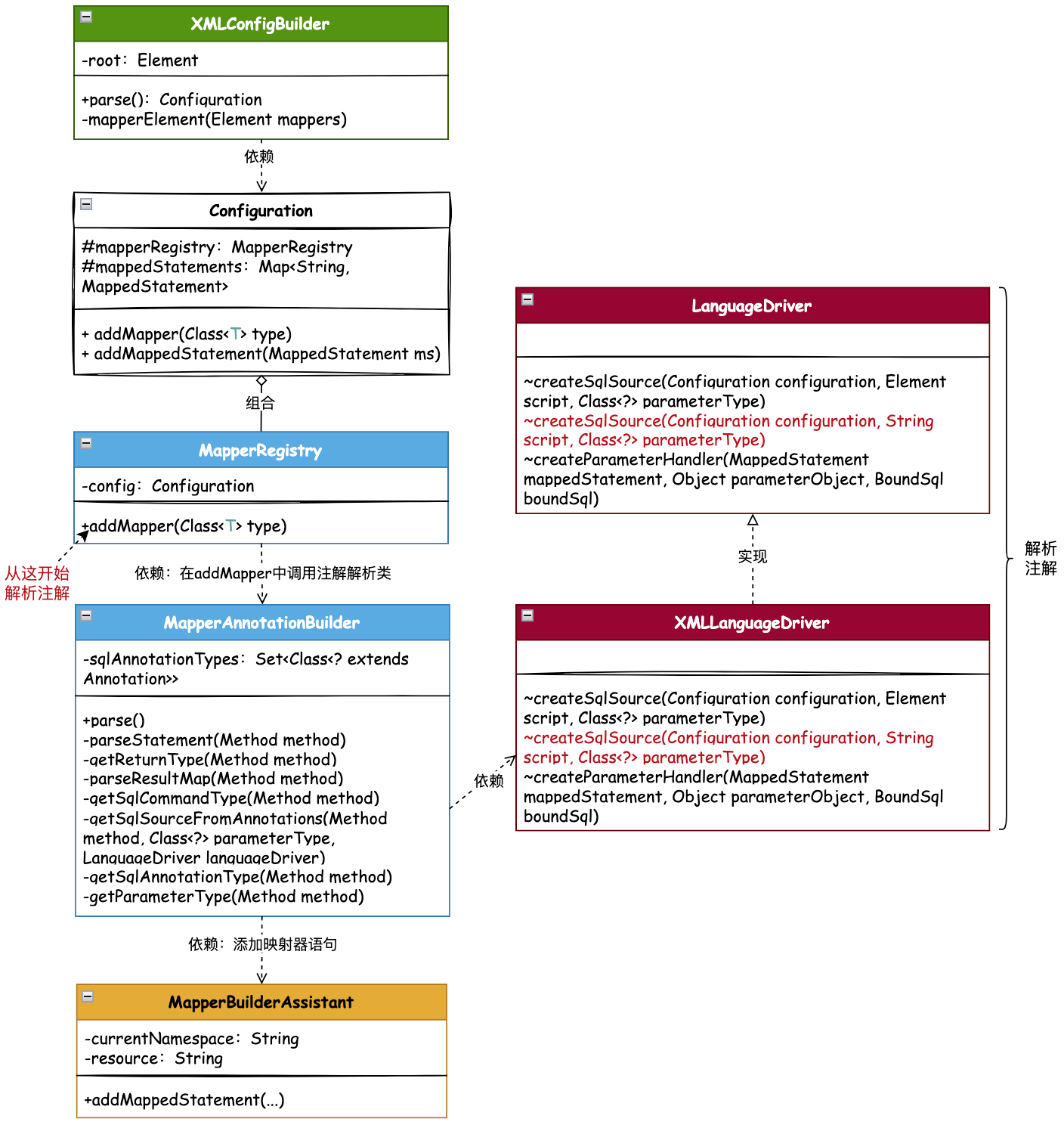
XMLConfigBuilder 配置构建器是解析 Mapper 的入口,以这条流程线中的方法 mapperElement 开始,处理 XML 解析的基础上,扩展注解的解析处理。
这里会通过从 xml 读取到的 class 配置,通过 Configuration 配置项类的添加 Mapper 方法,启动解析注解类语句的操作。也就是在 MapperRegistry 映射器注册机,随着 Configuration 配置项调用 addMapper 时所做的注解解析操作。
新增加的核心类 MapperAnnotationBuilder 注解配置构建器,就是专门以解析注解为主的类。注解方式的解析主要以通过 Method 类,获取方法的入参、出参信息,以及基于这样的信息,获取到 LanguageDriver 脚本语言驱动器,从而创建出 SqlSource 属性。那么到这里再往下执行的过程,就已经和前面章节一样了,获取 Mapper 调用 DefaultSqlSession 对应的方法,以及从 Configuration 配置项中获取到解析的 SQL 信息做相应的参数设置和结果包装操作。
脚本语言驱动器
LanguageDriver 脚本语言驱动,是在前面已经实现的功能,给配置在 Mapper XML 中的 SQL 语句进行解析创建 SqlSource 信息使用的。其中 createSqlSource 方法 script 的参数是 Element 用于解析XML文件的,而这里的注解方式则是通过 Method 方法进行解析,所以这里需要对这个方法进行重载,新增加一个参数 Method,用于解析注解方式的 SQL 语句。
源码详见:step12.mybatis.scripting.LanguageDriver
通过重载一个 createSqlSource 接口,把 script 的入参设置为 String 类型,来解析注解 SQL 的配置。
源码详见:step12.mybatis.scripting.xmltags.XMLLanguageDriver
- 用于解析注解方式的 createSqlSource 方法,其与 XML 解析来说,更加简单了。因为这里不需要提供专门的 XML 脚本构建器。而是直接按照 SQL 的入参信息,创建 RawSqlSource 即可。
- 在 Mybatis 框架的实现中,有专门一个 annotations 注解包,来提供用于配置到 DAO 方法上的注解,这些注解包括了所有的增删改查操作,同时可以设定一些额外的返回参数等。
定义注解
主要以带着读者贯穿整个使用注解下,Mybatis 对此类配置的处理和执行过程,所以我们这里只添加四个注解 @Insert、@Delete、@Update、@Select
源码详见:step12.mybatis.annotations.*
配置解析
源码详见:step12.mybatis.builder.annotation.MapperAnnotationBuilder
- 自定义注解的解析配置,主要在 MapperAnnotationBuilder 类中完成,整个类在构造函数中配置需要解析的注解,并提供解析方法处理语句的解析。而这个类的解析操作,基本都是基于 Method 来获取参数类型、返回类型、注解方法等,完成解析过程。
- 整个解析的核心流程包括;根据 Method#getParameterTypes 方法获取入参类型、从 Configuration 配置项中获取默认的 LanguageDriver 脚本语言驱动、以及基于注解所提供的配置信息,也就是 value 值中的 SQL 来创建 SqlSource 语句。
- 这些基本的信息创建完成以后,则根据 SqlCommandType 的命令类型为 SELECT 时,创建出 ResultMap 信息。这个 ResultMap 会被写入到 Configuration 配置项的 Map<String, ResultMap> resultMaps 中。这个是本章节在 Configuration 配置项中新增的方法
整体准备好这些基本的配置以后,则调用 MapperBuilderAssistant 映射构建器助手,存入映射器语句。通过完成以上这些参数解析的兼容,从这开始再往后的流程,就与前实现的过程一样了。 - 另外这里要注意 getReturnType(Method method) 方法的使用,它有一个非常核心的问题点,在于要拿到方法的返回类型,如果是普通的基本类型或者对象类型,直接就可以返回了。但有些时候因为集合类型,则需要通过 Collection.class.isAssignableFrom 判断,在进行集合中参数类型的获取,例如 List
则需要根据 method.getGenericReturnType() 获取返回类型,并判断是否为 Class 进行返回具体的类型。*这里不会返回 List,和使用 XML 配置 Mapper 是一样的,返回的类型resultType 都是对象类型 - 注解配置、解析处理,这些工作完成以后,接下来就是把解析放到哪一环来处理了。在 Mybatis 的源码中,是基于 XML 配置构建器解析 Mapper 时候进行判断处理,是 xml 还是注解。如果是注解则会调用到 MapperRegistry#addMapper 方法,并开始执行解析注解的相关操作。
解析策略调用
源码详见:step12.mybatis.builder.xml.XMLConfigBuilder
- 在 XMLConfigBuilder 配置构建器的 Mapper 解析处理中,根据从 XML 配置获取到的 resource、class 分别进行判断解析。
- 如果 resource 为空,mapperClass 不为空,则进行注解的解析处理。在这段代码中则是根据 mapperClass 获取对应的接口,并通过 Configuration#addMapper 方法,添加到配置项中。而这个 Mapper 的添加会调用到 MapperRegistry 进而调用注解解析操作。
解析注解调用
以 XMLConfigBuilder#mapperElement 解析调用 configuration.addMapper 方法开始,则会调用到 mapperRegistry.addMapper(type); 方法。那么接下来就到了处理注解类解析的操作。
源码详见:step12.mybatis.binding.MapperRegistry
- 在 addMapper 方法中,根据 Class 注册完映射器代理工厂后,则开始进行解析注解操作。这部分 MapperAnnotationBuilder 类的功能在前面已经讲解,到这里就把整个流程串联起来了。
总结
- 在原有解析 Mapper XML 的基础上扩展了使用注解方式的解析和处理,让整个框架功能更加完善。同时在扩展注解功能的结构时候,可以看到整个整合过程并不复杂,更多是类似模块式的拼装,通过开发出一个注解解析构建器,并在 Mapper 注册过程中完成调用和解析操作。
- 在整个内容的实现中,主要以串联核心流程为主,剔除掉一些分支过程。这主要是因为很多分支过程都是在处理一些各类场景的情况,而我们学习源码是需要掌握主脉络且不被太多的分支流程干扰的,才能把主干流程理顺。
- 通常在整个框架的实现过程中,会选取一部分逻辑进行处理,而不是把所有的 Mybatis 都搬过来。就像我们在处理注解时,只是添加了 @Insert、@Delete、@Update、@Select 这样四个注解。而 Mybatis 源码中,还有很多其他的注解,这些注解的处理逻辑,都是类似的,所以在学习的过程中,可以自己尝试去实现,这样才能更好的理解整个框架的设计和实现。

